Better & Faster Large Language Models via Multi-token Prediction
30 Apr 2024 https://arxiv.org/abs/2404.19737
Better & Faster Large Language Models via Multi-token Prediction
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each posi
arxiv.org
해당 논문은 Multi-token Prediction이라고 불리는 새로운 방식의 LLM 모델에 대하여 소개하고 있다.
Muti-token predciton은 기존 GPT 계열 LLM과 동일한 트랜스포머 구조를 기반으로 하지만 결정적으로 큰 차이는 여러개의 출력 헤드를 추가하여 여러 토큰을 동시에 예측하도록 학습되었다는 것이다.
즉, 일반적으로 GPT 및 Llama와 같은 LLM은 다음 토큰 예측(next-token prediction ) loss에 의해 학습되지만, 다음 토근 예측으로 학습된 모델의 경우, 몇가지 문제점을 가지고 있다고 해당 논문은 지적하고 있다.
1. 패턴을 지역적으로만 인식하고
2. '어려운' 결정을 간과한다.
결국, Next Token Prediction에 의해 학습된 LLM이 인간의 아이와 동등한 fluency에 도달하기 위해서는 훨씬 많은 양의 지식이 필요하다고 지적한다.
이 연구에서는 한 번에 여러 미래 토큰을 예측하도록 언어 모델을 훈련하는 방안을 제시하였으며, 이를 통해 저자들은 더 높은 sample efficiency을 가지고 더 성능이 높으며 더 빠른 모델을 개발하고자 했다.
Method
아래 그림을 통해 조금 더 구체적으로 확인하면, Trainingf Corpus의 각 위치에서 Shared model trunk 위에서 작동하는 n개의 독립적인 출력 헤드를 사용하여 다음 n개의 토큰을 예측하도록 모델을 학습한다.

이 과정에서 메모리 사용량이 커질 가능성이 존재하여 이를 제한하기 위한 방법을 도입하였다. 아래의 그림과 코드를 참고하여 확인하면 각 head의 gradient를 trunk에 누적하고 해제하여 head 수가 늘어나도 메모리 부담이 늘지 않도록 하였다.

이와 같이 Multi-token Prediction을 통하여 학습된 LLM은 학습 과정에서와는 다르게 기본적으로 나머지 예측 헤드를 제외하고 Next Token Prediction을 위한 출력 헤드만을 활용한다. 이 과정에서 Medusa(https://arxiv.org/abs/2401.10774)와 같이 Speculative decoding를 활용하여 여러 출력 헤드를 활용하여 Multi-token Prediction을 통한 출력도 구현되어 있다.
Result
1) Paramete 수에 따른 결과
본 논문에서 제안한 Multi Token Prediction의 경우, Model의 Parameter의 수가 크면 클수록 성능 지표가 개선된다.
그러나, Parameter의 수가 작을 경우 기존의 Model과 성능이 유사하거나 이보다 낮다고 한다.
2) 출력 헤드의 수에 따른 결과
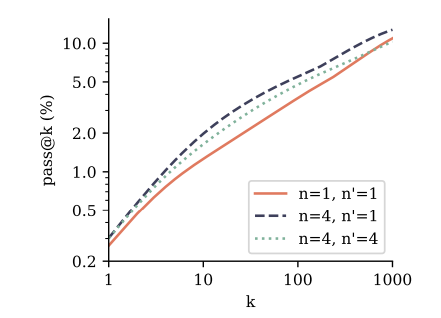
출력 헤드의 경우, 4~8개 사이에서 좋은 성능을 보임을 확인하였으며 8개 이상으로 출력 헤드를 증가시킬 경우 오히려 성능이 감소한다.

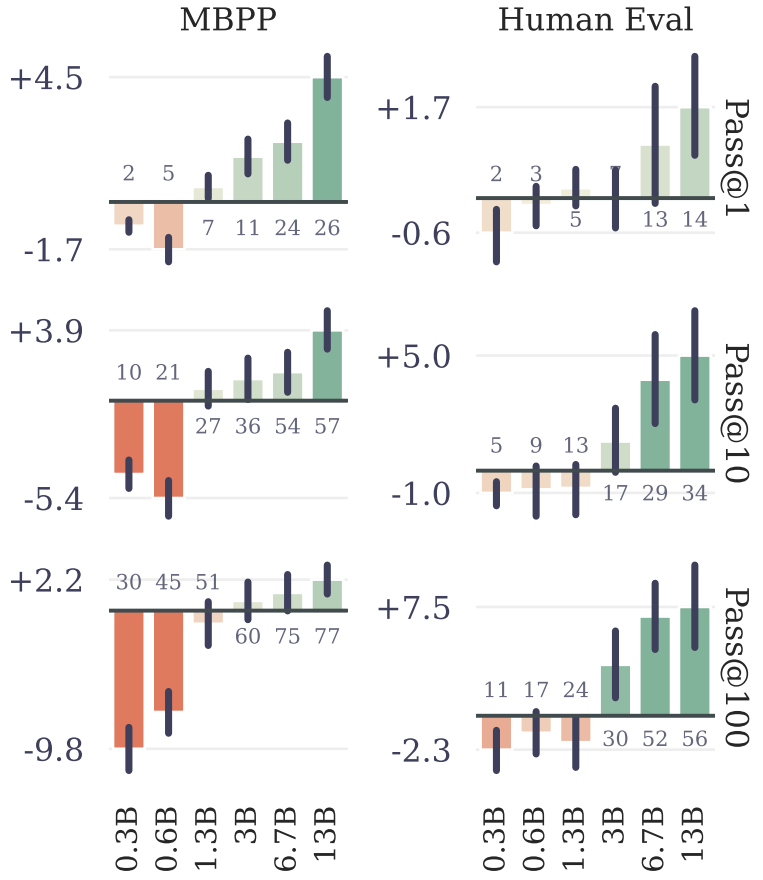
3) Task 별 성능 비교
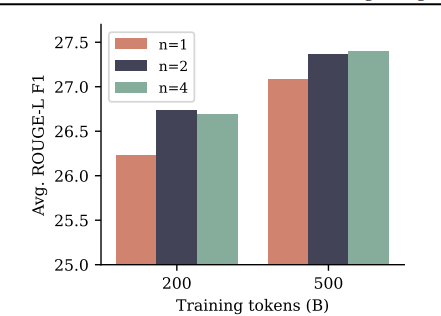
우선, CodeContests에 대한 성능 비교시, 학습시 출력 헤드, 추론시 출력 헤드를 동일하게 4개로 유지하였을 때 가장 성능이 좋았다. Summarization 성능 역시 출력 헤드의 개수를 4개로 하였을 때 가장 성능이 좋았다.
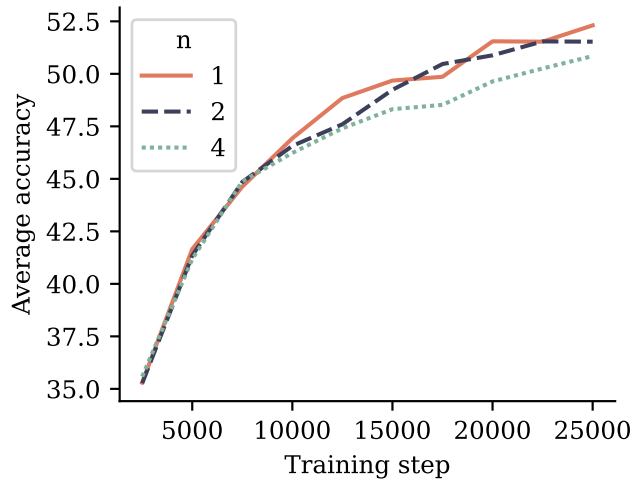
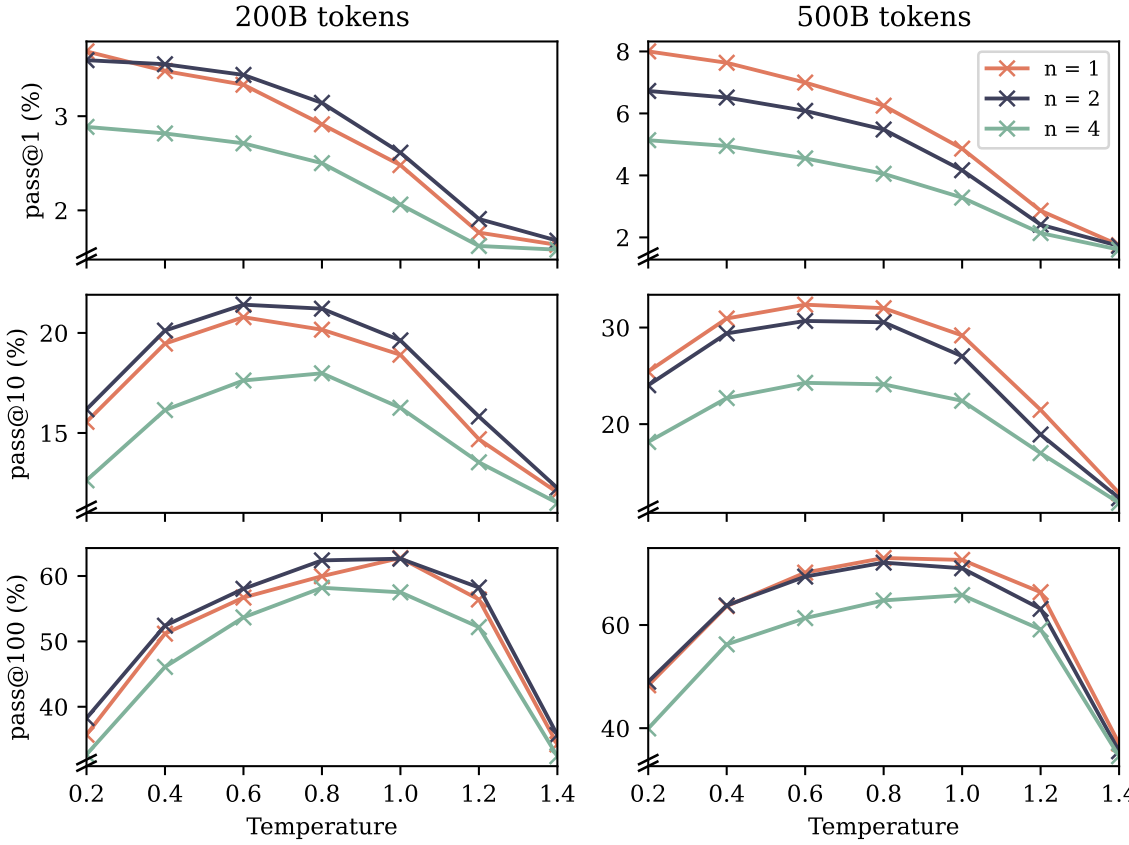
그러나, NLP task 중 Choice task와 수학 능력을 비교해 보았을 때 출력헤드를 증가하였을 때 오히려 성능이 떨어짐을 확인할 수 있다.
4) 활용법
Multi-token Prediction model의 경우 허깅 페이스에 학습 토큰 수 및 추론시 출력 토큰을 기준으로 4가지의 모델이 공개되어 있으며 Inference code를 모두 공개하고 있어 이를 활용하여 Multi-token Prediction model 활용하면 된다.
https://huggingface.co/facebook/multi-token-prediction
facebook/multi-token-prediction · Hugging Face
The information you provide will be collected, stored, processed and shared in accordance with the Meta Privacy Policy. MULTI-TOKEN PREDICTION RESEARCH LICENSE AGREEMENT 18th June 2024 This Multi-token Prediction Research License (“Agreement”) contains
huggingface.co
추론시, 필요 라이브러리는 아래와 같다
- torch
- fairscale
- fire
- sentencepiece
아래와 같이 입력시, Inference 가능
pip install huggingface_hub
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt install git-lfs
huggingface-cli login # 이후 huggingface api-key 입력
git lfs install
git clone https://huggingface.co/facebook/multi-token-prediction
pip install torch fairscale fire sentencepiece
torchrun --nproc_per_node 1 example_completion.py --ckpt_dir 7B_200B_4/ --tokenizer_path tokenizer.model --max_seq_len 128 --max_batch_size 2 # 경로 설정 필요
다른 내용의 추론을 원한다면 example_completion.py의 prompt 부분 수정 필요
from typing import Optional
import fire
from llama import Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.2,
top_p: float = 0.9,
max_seq_len: int = 256,
max_batch_size: int = 4,
max_gen_len: Optional[int] = None,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
prompts = [
# 이 부분의 수정 필요
"""\
def fizzbuzz(n: int):""",
"""\
import argparse
def main(string: str):
print(string)
print(string[::-1])
if __name__ == "__main__":"""
]
results = generator.text_completion(
prompts,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for prompt, result in zip(prompts, results):
print(prompt)
print(f"> {result['generation']}")
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)'A.I.(인공지능) & M.L.(머신러닝) > LLM' 카테고리의 다른 글
| [LLM]EXAONE3.0 (0) | 2024.08.09 |
|---|---|
| [LLM] 자기 추론 프레임워크 (0) | 2024.08.05 |
| LLM이 학습하면 기하급수적으로 성능 상향 하는 데이터(1) (0) | 2024.04.26 |
| [개념] sft & dpo 학습이 뭔가요? (0) | 2024.04.09 |
| [논문리뷰] Prompt 설정과 스키마 인식을 통한 향상된 SQL 쿼리 생성: PET-SQL (0) | 2024.04.04 |



