데이터는 초거대언어모델(LLM)과 생성형 AI를 움직이는 원유다
다량의 데이터는 생성형 AI와 초거대언어 모델(LLM)을 포함한 최신 인공지능 모델의 성능 최적화에 있어 결정적인 변수이다.
그러나 단순한 데이터의 양의 증가만으로는 인공지능 모델의 최적화를 달성하기는 어렵다. 우리는 데이터의 양만큼이나 질이 중요하다는 점을 간과해서는 안된다.
Garbage in, garbage out
품질이 저하된 데이터는 그 규모가 어마어마하더라도 원하는 성과를 가져오기 어렵다.
그렇다면 풀질 높은 데이터란 어떠한 특징을 갖추고 있어야 하는가?
일관성 있는 데이터
여기서 ‘일관성 있는 데이터는 통일된 표현법과 단위를 갖는 데이터를 의미하며, 이를 통해 유의미한 통찰력을 얻을 수 있다는 말이다.
그 외에도, 중복이 없는 독창적이며 정확하고 균형 잡힌 데이터를 '우수한 데이터'로 볼 수 있다. 특히, 학습 데이터의 균형은 중요한데, 편향된 데이터셋으로 학습된 모델은 잘못된 예측을 생성할 위험이 있다.
데이터의 가공 및 정제
또한, 데이터의 신뢰성을 확보하기 위한 정제 및 검증 과정은 불가피하다. 원본 데이터 내의 불필요한 또는 중복된 정보들은 데이터의 품질 저하의 원인이 되므로, 철저한 전처리 및 검증 절차를 거쳐야 한다. 이 과정은 실제 AI 모델 개발에서 중요한 비중을 차지하며, 데이터의 가공 및 정제는 모델의 성능에 결정적인 영향을 미친다.
데이터의 균형과 다양성
여러 소스에서의 수집이 필요하다. 단일 소스에서만의 수집은 데이터 내 편향을 초래할 수 있다. 이러한 접근 방식은 OpenAI의 ChatGPT와 같은 복잡한 모델에서도 적용되며, 다양한 웹사이트로부터의 매대 데이터 수집을 통해 다양한 문제에 대한 반응이 가능해진다.
본인 실습 과정 : 초거대 데이터 가공(한국어 170만개 문장)

엄청난 양의 한국어 데이터 셋을 확보했다!
분석 과정에서 데이터 셋 내에 서로 다른 유형의 데이터가 혼합되어 있는 것을 확인하였다.
17만 데이터셋(데이터 유형 동일) : distilbert/distilgpt2 · Hugging Face
Summary & Instruction-Answer
Sentence order inference
Original sentence inference
Last sentence prediction
Multi question
Mask Prediction
유형에 해당하는 데이터가 뒤섞여 있었다.
입력 및 출력의 형식이 일관되지 않고, 부정확한 instruction, output으로 작성되어 있었다.
이러한 데이터를 동일한 학습 프로세스에 포함 시킬 경우 모델의 성능 저하가 발생할 가능성이 있다.
이를 해결하기 위해 클러스터링을 통한 데이터 유형 분류 작업을 진행하였다.
분류 작업이 완료되면 데이터의 특성에 맞춰서 instruction 및 output 필드를 정제하고, 데이터 유형을 명확하게 정의하여 모델 학습의 효율성과 학습개선을 하고자 한다.
순서는 다음과 같다.
- instruction data embedding
- clustering / class
- data processing
Instruction embedding

10개의 데이터를 그냥 뽑아봤다.
수학을 묻는 질문도 있는 것을 볼 수 있다. 그냥 사람의 눈으로 18만개의 데이터를 분류하는 것은 불가능하다.
임베딩을 진행하였다. 사용한 모델은 아래와 같다. DistilGPT2는 GPT-2의 축소판이다.
임베딩 결과(instruction)
추출된 embedding 값들 통해 clustering을 진행하겠다.
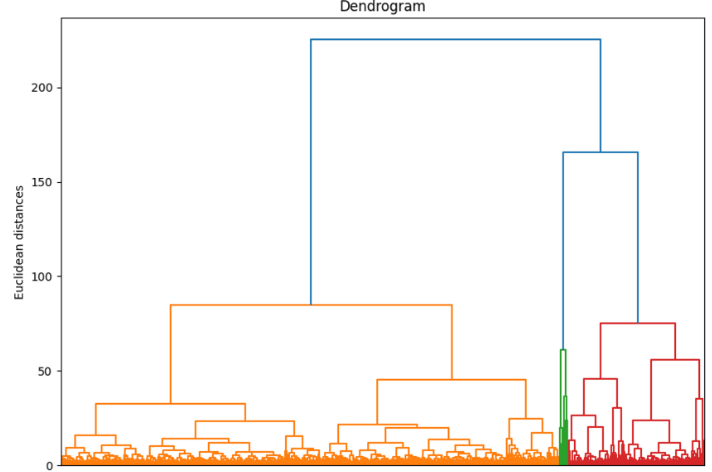
빠르게 작성하고자 임의로 1000개의 데이터를 추출하고 클러스터링을 진행하였다.
1000개의 데이터가 4개의 클러스터로 분류되었다.
클러스터끼리의 데이터를 확인해보겠다.




💡 데이터들을 봤을 때…
클러스터 0
이 클러스터는 개인적으로 생각했을 때 문장 생성에 오류가 발생한 거 같다. 지나치게 구체적인 질문이 작성된 것으로 보인다. 이런 데이터는 버리는게 나을 듯 싶다.
클러스터 1
정의를 요구하는 질문들로 구성되어 있는 거 같다. ‘무엇인가’에 대한 설명을 요구하는 질문이 많아, 이 클러스트는 폭넓은 범위의 일반적인 지식을 포함하는 것 같다.
클러스터 2
이 클러스터는 눈으로 봐도 파악되는, 수학적 문제 또는 복잡한 문제 해결을 요구하는 질문들로 구성되 있는 거 같다. 추상적인 사고와 고도의 분석을 필요로 하는 문제들을 포함하고 있다.
클러스터 3
더 개념적이거나 철학적인 질문이 포함되어 있는 거 같다. 예술, 문학, 인간 경험에 관련된 주제들이 보이며, 다른 클러스터들 보다 더 주관적이고 사색적인 내용을 다루는 거 같다.
하나의 데이터셋 안에서도 여러가지의 클러스터가 존재하며 이렇게 되면 서로 같이 학습되면 안되는 데이터 유형도 있기 마련일 것이다.

이렇게 따로 분류하고 모델을 학습할때는 같은 유형의 instruction을 이루고 있는 데이터셋을 넣어줘야 성능이 향상될 거이라고 생각된다. 또한 이렇게 비슷한 유형끼리 모여있으면 데이터 전처리(data processing)도 수월하게 진행할 수 있다.
다음에는 클러스트 별로 데이터 전처리(data processing)을 진행하여 더 좋은 데이터를 만들어보겠다.
'A.I.(인공지능) & M.L.(머신러닝) > LLM' 카테고리의 다른 글
| [LLM]EXAONE3.0 (0) | 2024.08.09 |
|---|---|
| [LLM] 자기 추론 프레임워크 (0) | 2024.08.05 |
| [논문 리뷰]Better & Faster Large Language Models via Multi-token Prediction (0) | 2024.07.08 |
| [개념] sft & dpo 학습이 뭔가요? (0) | 2024.04.09 |
| [논문리뷰] Prompt 설정과 스키마 인식을 통한 향상된 SQL 쿼리 생성: PET-SQL (0) | 2024.04.04 |



