LG AI Research에서 처음으로 공개한 오픈소스 LLM인 EXAONE(EXpert AI for EveryONE)3.0- 7.8B instruction tuned model이 공개되었다. 해당 모델을 공개하면서, 비슷한 크기의 오픈소스 모델보다 벤치마크 데이터 세트를 비롯해 여러 성능 평가에서 뛰어난 성능을 기록했다고 밝혔다.
1) 모델의 구조
EXA3.0은 최근 출시되고 있는 오픈소스 LLM인 Meta의 LLAMA-3.1(128k), mistral의 mistral-7B(32k)등과 비교했을 때 최대 컨택스트 길이는 상대적으로 작은 4k이다. 또한 최근 많은 LLM이 사용하는 구조를 차용하여 디코더 트랜스포머 구조를 활용하였고 Rotary Position Embedding(ROPE) 과 Grouped Query Attention (GQA)을 사용하였다. 자세한 모델 내용은 아래와 같다.

2) Tokenizer
해당 모델은 한국어 및 영어 두가지 언어에 대해서 학습을 하였고, 한국어의 경우 MeCab을 사용하여 한국어 코퍼스를 사전 토큰화하기 위해 특히 한국어의 교착어 특성을 고려했다. 그런 다음 어휘 크기가 102,400인 BBPE(바이트 수준 바이트 쌍 인코딩) 토크나이저를 처음부터 학습했는데, 영어의 압축 비율은 비슷하지만 기존 토크나이저에 비해 한국어의 압축 비율은 낮다.
압축 비율이 낮다는 것은 토크나이저가 단어당 생성하는 토큰이 적다는 것을 나타내며, 이는 과도한 토큰화 가능성을 줄여주기 때문에 유익할 수 있다. 한국어는 교착 구조를 가지고 있어서 여러 형태소가 결합되어 단어를 형성할 수 있으므로 모델 성능과 생성이 향상된다.

3) Pre-training
최근 LLM이 사전 학습 과정에서 수조개의 토큰에서 많게는 십조개 이상의 토큰을 활용하는 점에서 EXAONE3.0 또한 8조개 이상의 토큰을 활용하여 학습을 진행하였다고 밝혔지만, 단 대부분의 오픈 소스 거대언어모델이 그러했듯이 EXAONE3.0 역시 정확한 데이터 수집 경로에 대해서 밝히지 않았다. 대신 법적으로 문제 없는 방식을 활용하여 대규모 웹 크롤링, 공개적으로 사용 가능한 코퍼스, 내부적으로 구축된 코퍼스을 수집하였으며, 해당 데이터를 다음 규칙 기반 필터링, 머신 러닝 기반 필터링, URL 기반 필터링, 퍼지 중복 제거, 개인 식별 정보(PII) 제거를 통해 전처리하는 것 이외에도 여러 데이터 품질을 위한 처리 작업을 진행하였다고 밝혔다.
학습 데이터에 대해서는 비용 효율적 학습을 진행하기 위해 다양한 데이터 소스 및 속성을 활용하였고 데이터의 중요성과 분포에 따른 샘플링 비율 조정을 진행하였는데 우선, 범용적인 성능을 향상시키기 위해서 6T 토큰을 학습한 이후, 고급 언어 능력 및 전문 지식 향상을 위해 2T 토큰을 추가 학습하는 방식으로 진행하였다.
4) Post-training
사전 학습 이후 지시 수행 능력 향상을 위해, Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO) 두가지 방식을 활용하였다.
(1) Supervised Fine-Tuning (SFT)
학습 데이터를 구축하기 어렵기 때문에 광범위한 서비스 지향 지시를 포괄하기 위해 다양한 주제와 지시 기능을 정의하고 다양성과 적용 범위를 향상시키기 위해 광범위한 지시 유형을 개발했다. 또한 사용자와의 상호작용을 고려하기 위하여 Multi-Turn 데이터 세트를 적용했다.

(2) Direct Preference Optimization (DPO)
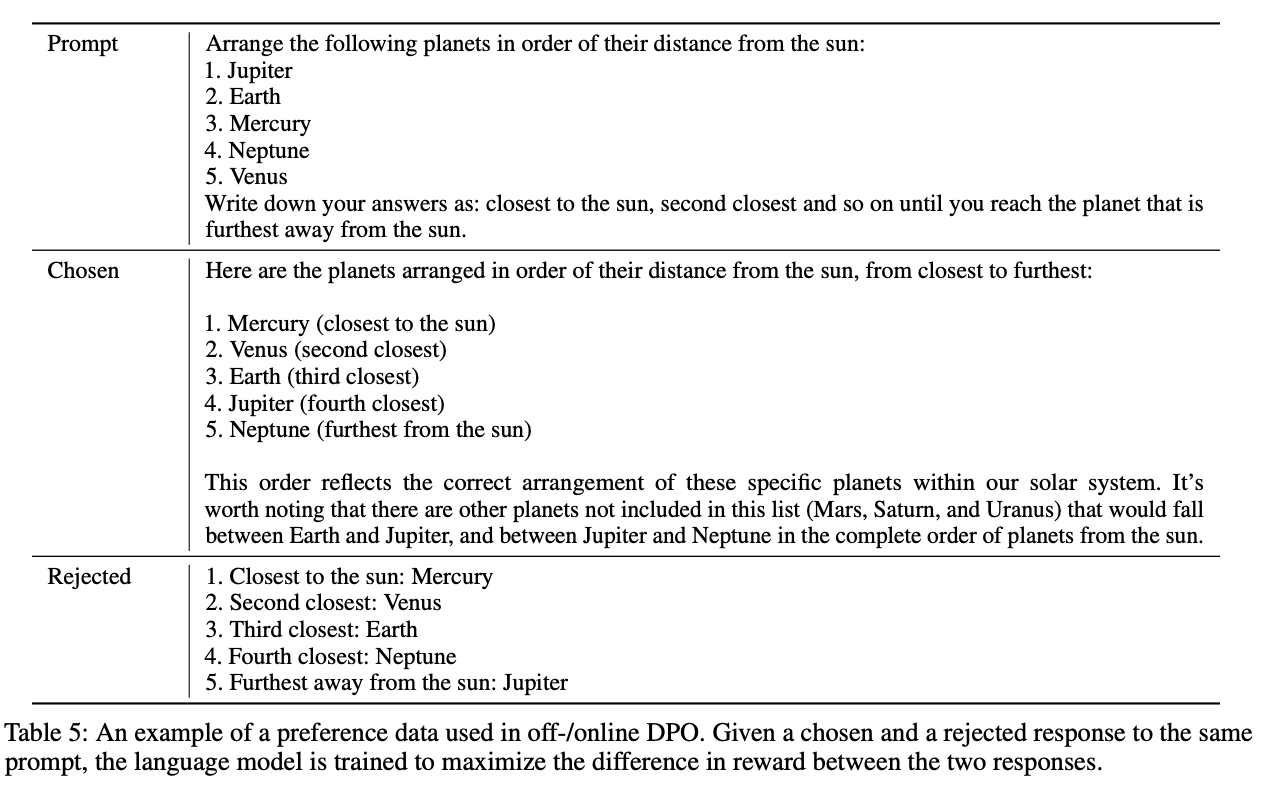
인간의 피드백을 사용하여 모델을 인간의 선호도에 맞추는 것인데, 이를 위하여 선호도 데이터 세트에서 선택한 응답과 거부된 응답 간의 보상 차이를 최대화하도록 학습되었다. DPO에는 오프라인 DPO와 온라인 DPO의 두 가지 방법이 있으며, 이를 순차적으로 적용했다. 오프라인 DPO는 미리 작성된 선호도 데이터를 사용하여 모델을 훈련하는 기술입니다. 반면 온라인 DPO는 오프라인 DPO를 통해 학습한 것과 유사한 데이터 분포를 갖도록 프롬프트를 구성하고, 모델이 응답을 생성하고, 보상 모델을 사용하여 선호도와 비교하여 평가하고, 응답에 선택 또는 거부 레이블을 지정하고, 결과를 다시 훈련에 사용하는 방식을 사용했다.
5) 학습 자원
Google Cloud Platform과 NVIDIA H100 GPU, NVIDIA NeMo Framework로 구동되는 클러스터를 사용하여 학습했고,그런 다음 NVIDIA TensorRT-LLM으로 최적화되었다.모델 학습에 사용된 총 계산량은 약 4 × 1023 FLOPS이다.
6) 평가
최신 LLM과 비교하였을 때, 코딩 및 한국어 성능에서 뛰어난 성능을 보였다.
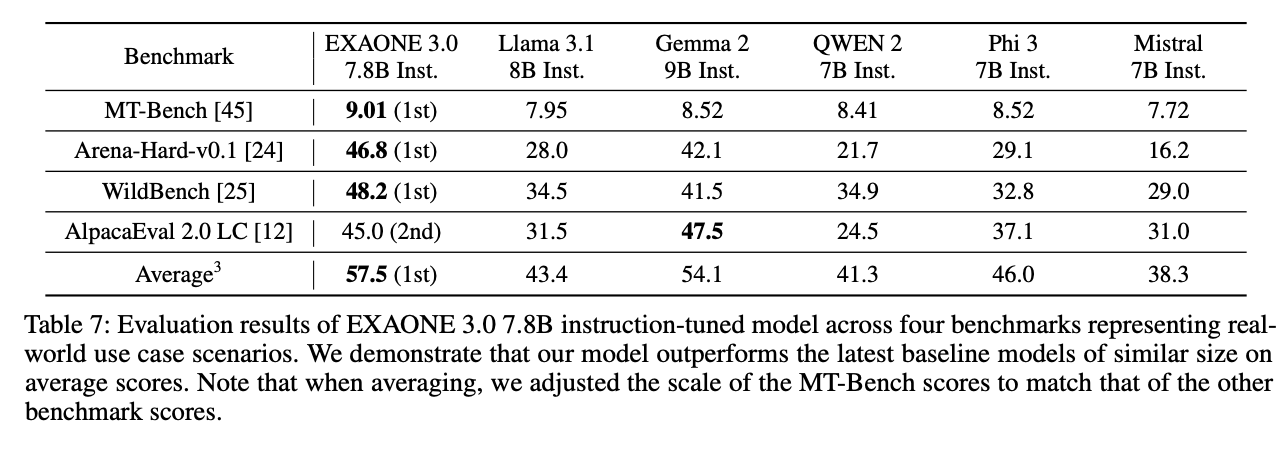
아래의 표는 실제 사용 사례에서의 평가로, 3가지 지표에서 가장 높은 성능을 보였으며 1가지의 지표에서는 두번째 높은 성능을 기록했다.
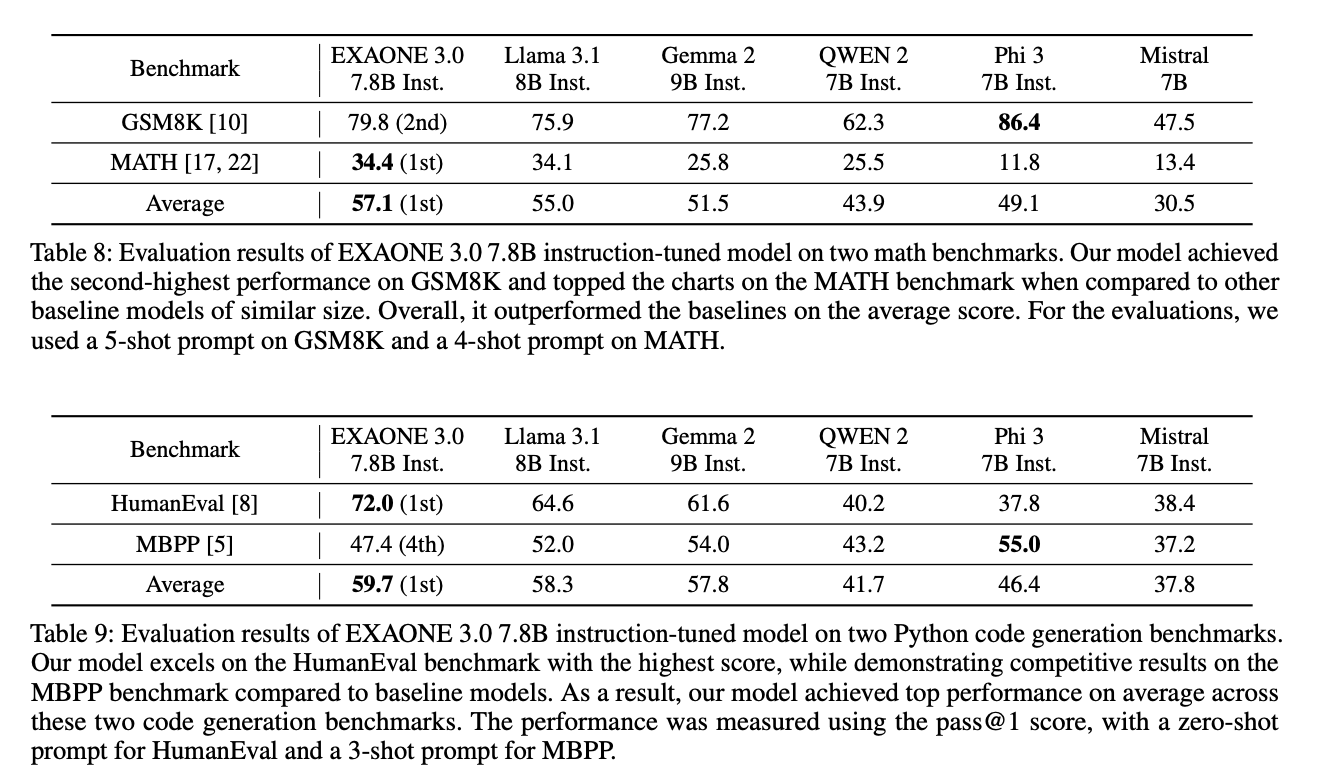
그 다음으로, 파이썬 코드 중 간단하면서 독립적인 함수를 생성하는데 초점을 맞춘 성능지표를 활용하였는데 이 지표들에서도 역시 뛰어난 비슷한 크기를 가진 거대 언어모델에 비하여, 높은 성능을 기록하였다
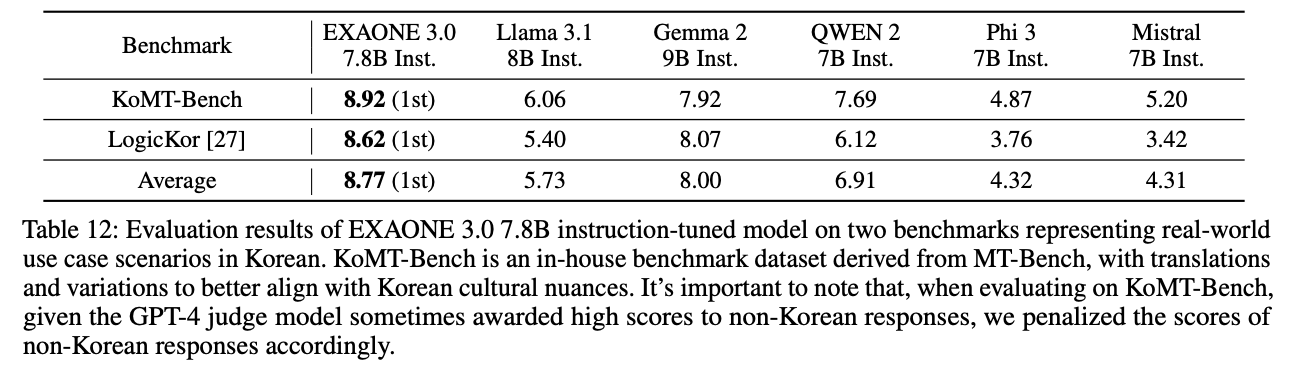
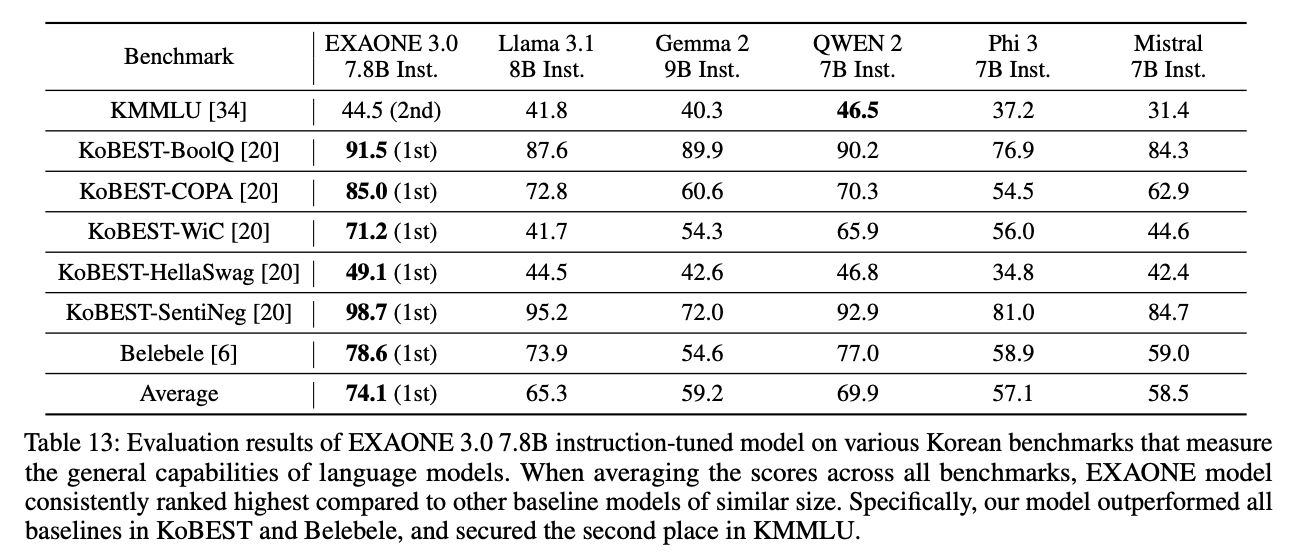
다음으로 한국어에서의 성능인데, 해당 모델이 2가지 언어(영어, 한국어)만을 학습하였다는 점을 고려하더라도 상당히 뛰어난 한국어 성능을 보인다. 아래의 표는 한국어를 대상으로 실제 사용 사례에 대한 평가인데 나머지 다국어 거대언어모델보다 굉장히 뛰어난 한국어 성능을 보여준다.
또한 종합적인 평가를 위하여 여러 성능 평가 지표를 활용하여 평가를 진행하였음에도 거의 모든 성능 지표에서 가능 뛰어난 성능을 보였다.
7) 실제 사용 방법
EXAONE-7.8B-Instruction 모델의 경우 허깅페이스에 공개되어 있으며 이를 이용해 간단하게 사용해볼 수 있다. 실제 사용 예시는 아래의 코드와 같다.
pip install transformers
pip install accelerate
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct")
# Choose your prompt
prompt = "Explain who you are" # English example
prompt = "너의 소원을 말해봐" # Korean example
messages = [
{"role": "system",
"content": "You are EXAONE model from LG AI Research, a helpful assistant."},
{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
)
output = model.generate(
input_ids.to("cuda"),
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=128
)
print(tokenizer.decode(output[0]))'A.I.(인공지능) & M.L.(머신러닝) > LLM' 카테고리의 다른 글
| Mergoo: 다양한 LLM 전문가를 신뢰성 있게 통합하는 방법 (1) | 2024.09.05 |
|---|---|
| [LLM]Mixture of Experts(MoE) (0) | 2024.08.21 |
| [LLM] 자기 추론 프레임워크 (0) | 2024.08.05 |
| [논문 리뷰]Better & Faster Large Language Models via Multi-token Prediction (0) | 2024.07.08 |
| LLM이 학습하면 기하급수적으로 성능 상향 하는 데이터(1) (0) | 2024.04.26 |



