컴퓨팅 성능의 발전, 초거대 언어 모델의 등장은 Natural Language Processing 분야를 비약적으로 발전시켰다.
그리고 이젠 어떻게 이미 만들어진 LLM을 고도화 시킬까의 문제를 마주하고 있다.
Chain of Thought 이후 생겨난 수많은 프롬프트들이나
Retrieval Augmented Generation 를 이용한 생성
이전에 소개한 LangChain이나 LangGraph도 결국 LLM을 효과적으로 사용하기 위한 Tool Chain이다.
오늘 소개할 것은 효과적인 지식 구조이자
최근에 만들어지는 RAG를 고도화 하는 새로운 기법인 GraphRAG이다.
Knowledge Graph
본 내용을 이해하기 위해서는 먼저 Graph에 대해 알아야 할 것이다.
물론 너무 깊게 들어갈 수는 없기에, 지식 그래프(Knowledge Graph)라는 것에 대해서만 알아보자.
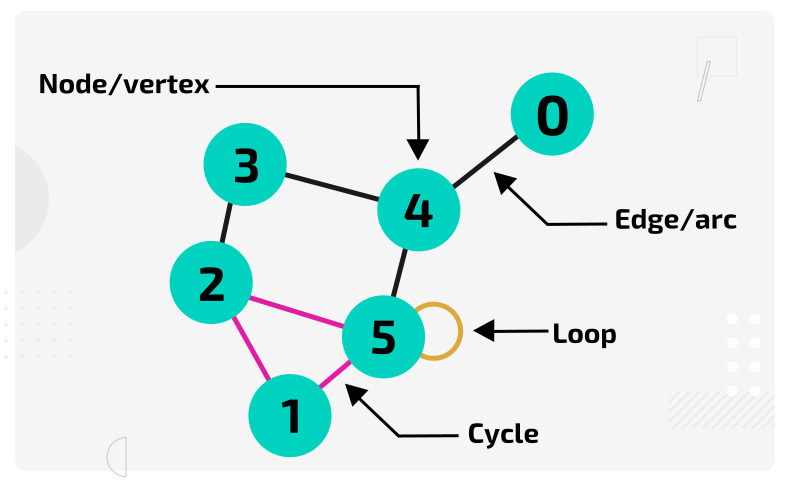
보이는 것은 그래프다.
Node와 Edge를 이용해 정보의 관계를 표현하는 하나의 지식을 담는 형태라고 볼 수 있겠다.
일반적인 그래프에서는 Edge는 단순한 연결만을 의미하고 있다.
해당 연결은 다양한 형태의 의미를 가질 수 있지만, 하나의 형태만을 취할 수 있다.
예를 들어 논문에서는 인용 관계만을 의미하거나
인물들에서는 교류 관계를 의미하거나 하는 등의 하나의 의미만을 내재한다.

레미제라블 인물 관계도를 예로 들어보겠다.
여기서 Node는 등장인물이며, Edge는 해당 등장인물들이 함께 등장한 것을 표현한다.
이 Edge의 Weight는 함께 등장한 횟수로 볼 수 있겠다.
매우 단순하지만 인물들의 관계를 아주 효과적으로 표현하고 있지 않은가?
지식 그래프는 앞서 설명했던 Edge의 한계를 뛰어넘기 위해 고안되었다.
즉 더 이상 Edge가 가지는 의미론적 형태가 하나로 고정되지 않는다는 것이다.
아래의 [모나리자와 관계된 그래프] 를 살펴보자.

이와 같이 더 이상 Edge는 하나의 의미를 가지지 않는다.
사람 간의 연결이 무엇을 의미하는지
사람과 장소의 연결이 무엇을 의미하는지
사람과 사물의 연결이 무엇을 의미하는지 등
기존에는 하나의 의미를 가졌던 연결들이 다양한 의미로 세분화되어 표현된다.
단순하게 모나리자와 다빈치가 연결되어 있다면, 우리는 그 관계를 무엇이라 볼 수 있는가?
일반적인 그래프에서는 이것이 그림과 화가의 관계라는 것을 표현할 수 없었다.
그러나 지식 그래프에서는 [Edge]에 [Knowledge]를 더함으로써 이를 가능하게 만들고 있다.
Graph Retrieval Augmented Generation
Graph RAG는 이러한 지식 구조를 효과적으로 이용하기 위한 기법으로
기존 Query Ebedding에 종속될 수 밖에 없는 RAG를 효과적으로 뛰어넘고자 한다.
[Microsoft의 Blog 포스팅]을 보면 기존 RAG는 몇 가지 문제가 발견된다고 한다.
기존 RAG는 정보의 점들을 연결하는데 어려움을 겪는다 (Struggles to connect the dots).
이는 다양한 정보 조각들의 공유 속성을 통해 종합적인 통찰력을 제공해야 하는 경우에 발생한다.
기존 RAG는 거대한 데이터 컬렉션이나, 단일 대규모 문서로부터 요약된 의미론적 개념을 이해하는데 어려움을 겪는다.
(Holistically understand summarized semantic concepts over large data collections or even singular large documents).
이러한 현상은 두 가지 결과를 말해준다고 볼 수 있는데 ...
먼저 LLM은 매우 강력한 도구라는 것이다. 갑자기 무슨소리인가 하면 ...
LLM은 정확한 정보만 "제공"된다면 사실상 의미를 이해하고 생성하는 것에 크게 어려움이 없다는 것이다.
그럼 결국 문제는 뭐냐? RAG에 내장된 Retrieval. 즉 검색 기능 자체가 문제가 있다고 보는 것이 타당하다.
기존의 RAG는 LLM에게 필요한 정보를 효과적으로 제공하지 못하고, 그 때문에 문제가 발생한다고 보는 것이다.
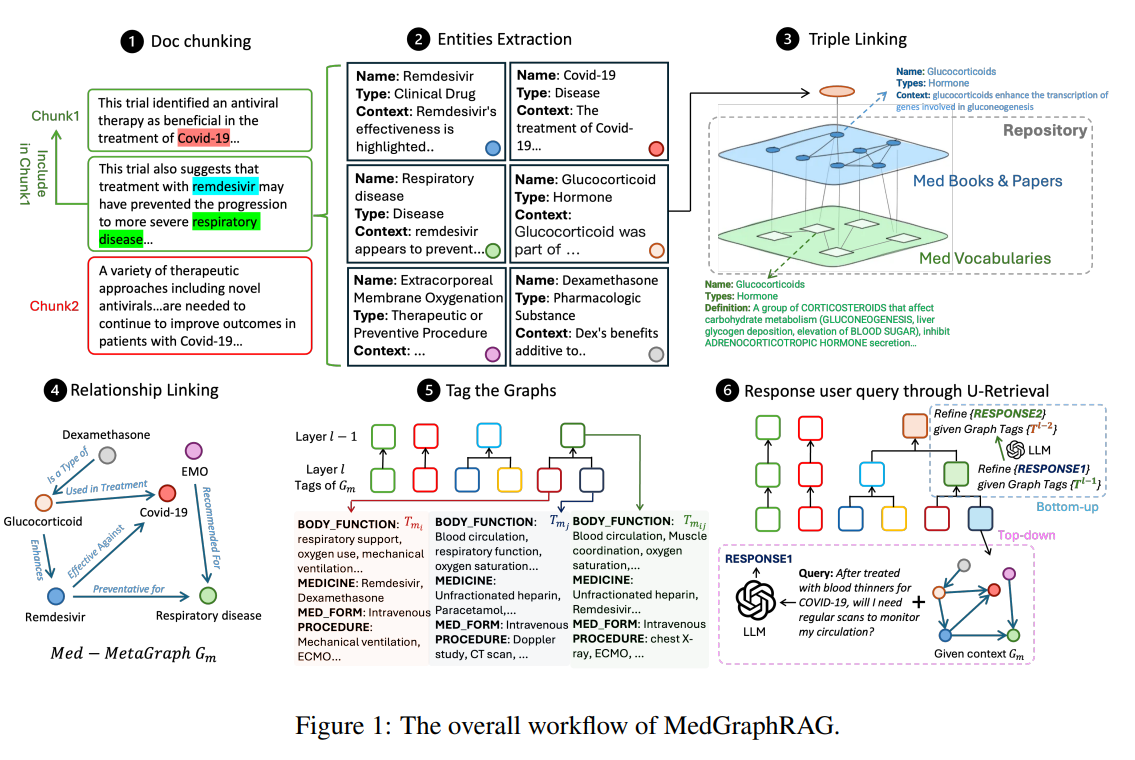
Medical 분야는 매우 경직된 분야로, 생명과 관계된 정보를 다루기 때문에 매우 견고한 지식 구축이 필요하다.
[상기된 연구] 는 Medical 분야에서 GraghRAG를 구축하는 방법을 소개하고 있다.
여기서 주요하게 살펴볼 것은 그림의 2번에 보이는 Entities Extraction와
4번에서 볼 수 있는 Relationship Linking이라고 볼 수 있다.
본문에서는 난잡한 수식으로 설명하고 있지만 간단하게 이해해보면 ...
- 가장 먼저 주어진 정보 청크 H로부터, 개별적인 Information 조각인 e를 생성한다.
- 청크 H는 조각 e의 Reference가 되도록 연결을 생성한다.
- 청크 H 내부의 조각 e 간의 관계를 조사하여 연결을 생성한다.
이 과정을 통해 전체적인 지식 그래프의 뼈대를 구성하게 되는데 ...
실제로 가장 좋은 방법은 인간 전문가나 강력한 Reference를 이용해 모든 과정을 진행하는 것이 좋다.
그러나 해당 연구에서는 Prompt와 LLM을 이용해 해당 과정을 모두 진행하고 있음을 알 수 있다.
(물론 간편하지만, 해당 연구는 다루고 있는 분야가 Medical 분야이기 때문에 좀...)
이것 또한 매우 고무적인데 .. 실제로 Graph를 다루는 데 있어 가장 어려운 것이
정제된 그래프를 구축하는 것 자체에 있다.
지식 그래프가 강력하다는 것은 오래전부터 자명하지만, 해당 그래프를 구축하는 것은 코스트가 너무 큰 문제가 있었다.
어떻게 보면 해당 연구의 가장 큰 Contribution은 LLM으로 구축한 지식그래프만 활용해도 LLM의 성능이 향상될 수 있다는 것을 증명했다는 것에 있지 않을까 싶다.
Graph Retrieval
지식 그래프가 무엇인지 살펴보고, 최근 LLM을 활용한 연구가 어떻게 지식 그래프를 구축하는지 살펴봤다.
마지막은 그러면 이렇게 구축된 지식을 LLM이 어떻게 찾을 것이냐는 것이다.
상기된 연구에서는 Tag를 활용한 방식을 이용한다 (필자들이 U-Retrieval 이라고 부른다 ...)
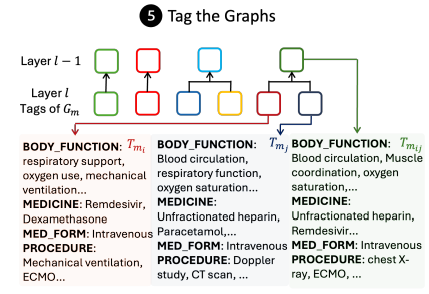
먼저 그래프 구축 당시에 위와 같이 Tag를 적절하게 입력해둔다.
이후 인간 Q가 입력되면, LLM과 Prompt를 통해 T_Q를 먼저 추출하게 된다.
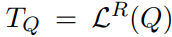

이후 상기 그래프로부터 T_Q와, T^i[j]의 유사도를 최대화 할 수 있는 Tag를 찾아 Layer를 탐색하게 된다.
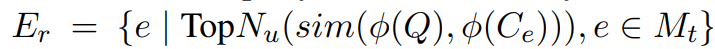
Tag를 먼저 찾고, 아까 생성한 정보 조각 e와 Query와의 Ebmedding 유사도가 높은 것을 가져오게 된다.
이렇게 생성된 정보 조각의 집합이 하나의 입력 Retrieval로 작동하게 되고
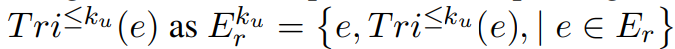
해당 정보조각들과 연결되어 있는 Neigbor Node의 정보까지 함께 가져오게 된다.
이는 사실상 가장 쉽게 생각할 수 있는 효과적인 Retrieval 방식 중 하나라고 볼 수 있는데
실상 Graph에 존재하는 모든 지식 노드들을 탐색하는 것은 매우 비효율적이고 불가능하다.
그렇기 때문에 연구자들은 Tag를 이용하여 정보의 탐색 범위를 제한하고 있다고 볼 수 있겠다.
몇 가지 다른 연구들도 비슷한 접근 방식을 취하고 있는데
[LEGO-GraphRAG] 에서는 3가지의 모듈적 접근 방식을 통해 데이터를 추출한다.
간단하게만 살펴보자.
가장 먼저 [Subgraph-Extraction]을 진행한다.
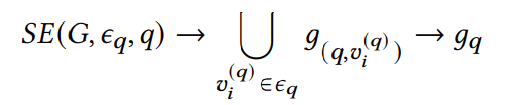
SE의 목적은 이전에 말한 것과 같이, 전체 그래프로부터 Small-Sclaed Subgraph를 구성함으로써
Search Space를 감소시키는 것이 목적이다.
해당 연구에서는 Query 기반 Search를 통해 연관된 Subgraph를 찾고
해당 Subgraph를 모두 합처 최종적인 Search Space를 구성하게 된다.
(실제로 해당 과정은 Personalized PageRank; PPR이나 Random Walk with Restart 등의 알고리듬을 이용한다.)
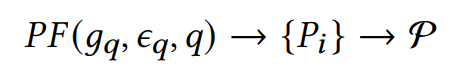

이후 [Path-Filtering]을 통해 주어진 Subgraph g로부터 최적의 Reasoning path P를 찾는다.
이 과정은 주어진 쿼리로부터 발견되는 Entities를 통해 해당 서브그래프 내부에서 경로를 탐색하는 알고리듬이다.
실제로는 BFS, DFS와 같은 Complete Path-Filtering 알고리듬을 이용하거나
Dijkstra 탐색 알고리듬과 같은 Shortest Path-Filtering 알고리듬,
Beam Search 와 같은 Iterative Path-Filtering 알고리듬을 이용하여 진행하였다고 한다.
마지막인 [Path-Refinement]의 경우에는 앞서 구해진 Set of Path P로부터 가장 적절한 경로 하나만을 남기는 과정이다.
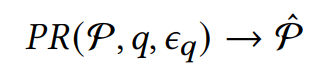
실제로 무엇이 관여하는지 자세하게 설명하고 있지는 않았는데 ...
뒤에 표를 보면 아마도 LLM과 Prompt를 통해 하나만을 남기도록 설정하고 있는 것으로 보인다.
[다른 연구 하나] 에서도 똑같은 방식을 사용한다.
GNN-RAG라 불리우는 해당 연구는 마찬가지의 접근을 취한다.
- 사용자의 Query로부터 밀집된 서브그래프를 추론하여 검색 후보를 한정한다.
- 해당 검색 후보군으로부터 Query에 가장 적절한 경로를 탐색한다.
본 포스팅에서는 GraphRAG가 이와 같은 비슷한 맥락의 접근을 취하고 있다는 것만 보고 넘어가자.
다음에는 GraphRAG를 이용한 Grahp를 만들어 보고
일반적인 RAG와 비교하였을 때의 성능을 검증해 보도록 하자.



