관련 시리즈
- 2024.11.11 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 1. LangGrpah(랭그래프)를 이용한 AI Workflow 관리하기
- 2024.11.13 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 2. LangGrpah(랭그래프)의 핵심 요소의 개념적 이해
- 2024.11.14 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 3. Chain과 Agent를 이용한 Workflow 구현 - 쿼리 추출 모델
- 2024.11.20 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 4. LangGraph를 이용한 RAG 및 검색 Agent 개발 (현재글)
이번에는, 이전에 구현한 것과 더불어 RAG 및 검색 기능까지 내장된 Agent를 설계해보도록 하자.
먼저 전체적인 Workflow를 살펴보자.

상당히 복잡한 Workflow를 띄고있지만, LangGraph의 핵심은 이러한 전체 과정을 손쉽게 살필 수 있다는 것이다.
이전과 다르게, 여기서의 핵심은 'Chracter Make' Node라고 볼 수 있다.
우리는 적절한 인공 페르소나를 만들어, 해당 페르소나가 쇼핑에서 어떤 검색을 하게될지 알아보고 싶다.
이러한 적절한 페르소나를 만들기 위해서는, 해당 페르소나에 어울리는 적절한 캐릭터 설명이 필요하다고 판단하였다.
즉, 해당 과정이 전체 품질을 결정하는 핵심 작업이 되고, 이를 완성도 있게 작성하기 위하여
아래의 3가지 핵심적인 요소들을 통해 품질을 보강하고 있다.
- Chracter Make Tool (검색을 통한 정보 탐색)
- RAG Tool 및 Chracter Retrieve Check (미리 입력된 RAG 정보를 탐색하고, 해당 RAG가 적절한지 판단)
- Rewrite Tool 및 Rewrite-Search (RAG가 적절하지 않은 경우, 검색 문장을 적절하게 재작성하고 웹 탐색)
이는 두 가지 모듈을 결합한 것으로
하나는 일반적인 웹 서치를 통한 생성 보강 모듈이며 (LangGraph-가이드),
두 번째는 Corrective RAG를 활용한, db 탐색 및 검증-보강 모듈이다 (논문 / 가이드)
그러면 하나하나 살펴보도록 하자.
1. Chroma db를 이용한 RAG 기능 구현
import os
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
with open('API_KEY.txt', 'r') as api:
os.environ["OPENAI_API_KEY"] = api.read()
urls = [
"https://the-edit.co.kr/65111",
"https://blog.naver.com/sud_inc/223539001961?trackingCode=rss",
"https://mochaclass.com/blog/직장인을-위한-취미생활-가이드-요즘-취미-트렌드부터-취미-추천까지-7797",
"https://www.hankyung.com/article/2024072845441",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
persist_directory="./chroma_db",
)
vectorstore.persist("./chroma_data")
먼저 다음과 같은 형식으로 Document를 정리하였다.
url은 예시를 위해 임의로 사용하였다. 더 정확한 Agent를 만들기 위해서는 좋은 정보만 담아야 한다.
부정확한 정보를 넣어주면, 처리시간 및 답변 품질이 떨어질 수 있다.
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
# 청크의 크기
chunk_size=100,
# 청크 간 중복되는 부분이 얼마나 가능한가
chunk_overlap=50,
)
청크를 나누는 splitter에 따라서도 품질이 결정되기도 한다.
chunk의 size가 너무 작으면 충분한 의미를 context에 제공하지 못하기도 하며
overlap이 없다면 잘려나가는 부분이 생기기도 한다.
적절하게 조절하는 것이 중요하다.
여기서는 부정확한 결과를 제시하여 재검색하는 Method를 시연하기 위한 예시이므로 각각 100과, 50을 주었다.
(300 이상은 주어야 적당한 Context가 제공되는 것으로 보인다)
이렇게 하면 URL로 제공된 데이터를 이용한 RAG 준비는 완료이다.
# RAG 기능을 사용하는 Node 설계
# 먼저 저장한 DB의 데이터를 불러온다.
# 임베딩 함수로는 openai의 임베딩을 사용하였다.
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.tools.retriever import create_retriever_tool
from langgraph.prebuilt import ToolNode
vectorstore = Chroma(
collection_name="rag-chroma",
embedding_function=OpenAIEmbeddings(),
persist_directory="./chroma_db",
)
retriever = vectorstore.as_retriever()
# 해당 툴을 정의하는 것.
# 이를 이용하여 LLM에 해당 툴을 결합시킬 수 있음.
retriever_tool = create_retriever_tool(
retriever,
# 해당 retriever이 tool call에 의해 호출되는 경우, 해당 tool의 이름
"retrieve_trends",
# 해당 tool을 호출해야하는 상황을 Agent가 판단할 수 있도록 지시
"Search for the latest trends in fashion and hobbies and return relevant information.",
)
# 해당 툴 노드를 정의하는 것.
# Graph에서 사용하기 위해 Node로 만들 필요가 있음.
retrieve = ToolNode([retriever_tool])
먼저 저장한 db를 불러온 뒤,
해당 db를 이용하여 retriever tool을 정의해 주었다.
이를 정의할 때, 해당 Tool의 이름과, 해당 툴을 사용하여야 하는 상황에 대해서 Instruction을 넣어주어야 한다.
마지막으로 LangGraph의 툴 노드 class를 이용하여 해당 노드를 정의해주었다.
##### STATE #####
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
class PersonaState(TypedDict):
user_input: str
messages: Annotated[list, add_messages]
character_persona_dict: dict
retrieve_check: bool
retrieval_msg: str
rewrite_query: str
##### NODE #####
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import HumanMessage, ToolMessage
character_model = ChatOpenAI(model="gpt-4o", temperature=0.2)
character_model_with_tools = character_model.bind_tools([retriever_tool])
def character_make_node(state: PersonaState):
prompt_with_tools = ChatPromptTemplate.from_messages([
("system","""
You are an expert in creating characters for fiction.\n
Whatever input the user is presented with, you must return a description of the completed character.\n
If no information is available, randomly generate and return the character's attributes.\n
Based on the values entered by the user, envision and present the character, including the character's age, gender, job, location, interests, hobbies and etc.\n
If you have difficulty creating an appropriate character, use an online search to solve the problem.\n
The returned value must be in Korean.\n
"""),
("human", "Input: {human_input}\n Retrieve: {context}"),
])
# 이전에도 설명했듯 state의 add_messages 함수는 계속해서 뒤로 메세지를 추가하는 형식
# Tool은 사용된 뒤 ToolMessage를 반환하는데, 이것이 add_message를 통해 뒤에 삽입됨
# 따라서 Tool이 제공한 값을 사용하기 위해서는 state의 messages속 가장 마지막 인자를 받아야 함.
# 다만 이러한 경우 마지막 메세지가 HumanMessage일 가능성도 있으므로, 이를 검증하고 진행.
messages_list = state['messages']
last_human_message = next((msg for msg in reversed(messages_list) if isinstance(msg, HumanMessage)), None).content
last_msg = state['messages'][-1].content
# 이전 메세지 속 ToolMessage가 없는 경우
if last_human_message == last_msg:
last_msg = ""
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}")
# 이전 메세지 속 ToolMessage가 있는 경우
# 이 경우 받아온 tool message의 content가 str 형식인 경우가 있어, json으로 변환
else:
try:
last_msg_data = json.loads(state['messages'][-1].content)
last_msg = "\n\n".join([d["content"] for d in last_msg_data])
except:
...
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}\nContext: {last_msg}")
chain_with_tools = prompt_with_tools | character_model_with_tools
response = chain_with_tools.invoke({"human_input": last_human_message, "context": last_msg})
# Tool을 호출하는 경우 AI는 빈 str과 tool_calls인자를 반환하게 된다.
# 즉 content = ""이 반환되고, tool_calls에는 호출한 Tool과 관련된 정보가 담겨 있다.
# 이를 검증하여 어떠한 Tool이 호출되었는지 표지할 수 있다.
if hasattr(response, "tool_calls") and len(response.tool_calls) > 0 and (response.tool_calls[0]["name"]) == "retrieve_trends":
print("=============================== Search Retrieval ===============================")
else:
print("============================= Chracter Information =============================")
print(response.content)
return {"messages": [response], "user_input": last_human_message}
이렇게 작성한 경우, 해당 노드는 아까 만들어 둔 retrieve라는 Tool을 자신의 판단에 의해 사용하게 된다.
만약 주어진 정보로 작업을 수행할 수 있다면, 바로 답변을 작성하게 되고
이것이 불가능한 경우 tool_calls이 담긴 AIMessage를 response로 제공하게 된다.
##### EDGE #####
def simple_route(state: PersonaState):
"""
Simplery Route
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
# 만약 주어진 AIMessage에 RAG 기능 호출이 존재한다면, 'retrieve'를 반환
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0 and ai_message.tool_calls[0]["name"] == "retrieve_trends":
print("Retrieve Call")
return "retrieve"
# 아닌 경우 'next'를 반환
return "next"
# 반환된 값에 따라 어떤 노드로 이동할지를 결정하는 것.
graph_builder.add_conditional_edges(
"Character Make",
simple_route,
{"next": "Persona Setup", "retrieve": "RAG Tool"}
)
message를 반환한다는 것을 알았다면, routing을 구현하는 것은 매우 간단한다.
주어진 message가 tool_calls를 가지고 있는지 아닌지를 검사하여 다른 값을 반환해주면 된다.
만약 Tool이 여러개 존재하게 된다 하더라도, 같은 방식으로 라우팅을 구현할 수 있다.
2. Tavily Search를 이용한 검색 기능 구현
Tavily를 이용한 검색 기능을 구현하는 것을 라이브러리가 상당히 잘 되어있기 때문에 어렵지 않은 작업이다.
이번 포스팅에서는 기본적인 구현과 함께 RAG와 동시에 제공되는 경우 등을 살펴보고 있다.
import os
from langchain_community.tools.tavily_search import TavilySearchResults
from langgraph.prebuilt import ToolNode
with open('./api_key/TAVILY_API.txt', 'r') as api:
os.environ["TAVILY_API_KEY"] = api.read()
tool = TavilySearchResults(max_results=3)
tool_node = ToolNode(tools=[tool])
Tavily Search 기능을 가진 Node를 구현하는 것은 매우 간단하게 이뤄진다.
이렇게 구현된 노드는 자동으로 이전 HumanMessage를 이용하여 Search를 진행하는 기능이 담겨있다.
해당 기능을 사용하기 위해서는 TAVILY_API_KEY를 입력해주어야 한다.
tool.invoke("랭그래프가 뭐야?")
##### output
[{'url': 'https://m.blog.naver.com/dabomai/223605684205',
'content': "랭그래프가 무엇인가? 2달 전에 랭체인을 공부할 수 있는 기회를 얻었습니다. 항상 '공부해야지~공부해야지~' 하다가 시간이 나서 이때다 싶어 바로 Docs를 키고 튜토리얼을 따라 하며 공부했습니다. 이때 전까지만 해도 랭체인에서 지원하는 RAG, 대화 기록 보존"},
{'url': 'https://teddylee777.github.io/langchain/langchain-tutorial-08/',
'content': '⑥ 테스트\n태그:\nChatGPT,\nChatOpenAI,\nGPT3.5,\nGPT4,\nlangchain,\nlangchain tutorial,\nOpenAI,\nPDF,\n랭체인,\n랭체인 튜토리얼,\n문서요약,\n질의응답,\n크롤링\n카테고리:\nlangchain\n업데이트: 2023년 10월 13일\n참고\n[Assistants API] Code Interpreter, Retrieval, Functions 활용법\n2024년 02월 13일\n35 분 소요\nOpenAI의 LangChain 한국어 튜토리얼\n바로가기 👀\n랭체인(langchain) + PDF 기반 질의응답(Question-Answering) (8)\n2023년 10월 13일\n2 분 소요\n이번 포스팅에서는 랭체인(LangChain) 을 활용하여 PDF 문서를 로드하고, 문서의 내용에 기반하여 질의응답(Question-Answering) 하는 방법에 대해 알아보겠습니다.\n 후반부에는 langchain hub 에서 프롬프트를 다운로드 받고, 이를 ChatGPT 모델과 결합하여 문서에 기반한 질의응답 Chain 을 생성합니다.\n✔️ (이전글) LangChain 튜토리얼\n🌱 환경설정\n🔥 PDF 기반 질의 응답(Question-Answering)\n다음은 비구조화된 데이터를 QA 체인(Question-Answering chain) 으로 변환하는 파이프라인에 대한 기술적 번역입니다:\n데이터 로드: 우선, 데이터를 로드해야 합니다. 특히, Assistant API 가 제공하는 도구인 Code Interpreter, Retrieval...\n[LangChain] 에이전트(Agent)와 도구(tools)를 활용한 지능형 검색 시스템 구축 가이드\n2024년 02월 09일\n41 분 소요\n이 글에서는 LangChain 의 Agent 프레임워크를 활용하여 복잡한 검색과 문서 기반 QA 시스템 설계 방법 - 심화편\n2024년 02월 06일\n23 분 소요\nLangChain의 RAG 시스템을 통해 문서(PDF, txt, 웹페이지 등)에 대한 질문-답변을 찾는 과정을 정리하였습니다.\n'},
{'url': 'https://velog.io/@kwon0koang/로컬에서-Llama3-돌리기',
'content': '1부. 랭체인 (LangChain) 정리 (LLM 로컬 실행 및 배포 & RAG 실습) 2부. 오픈소스 LLM으로 RAG 에이전트 만들기 (랭체인, Ollama, Tool Calling 대체)'}]
이렇게 정의된 TavilySearchResults Class는 invoke를 통해 간단하게 검색이 가능하다.
해당 Tool 또한 RAG와 마찬가지로 Name과 Description을 가지고 있다.
기본적으로 존재하나, 수정을 통해 여러가지 테스트를 수행해 볼 수 있다.
여기서는 기본값을 사용한다.
tool = TavilySearchResults(
# tool을 호출 하는 경우 어떤 이름으로 호출할지에 대한 것. 기본값은 tavily_search_results_json 임
name="example_tavily_name",
# 해당 Description이 기본값
description="A search engine optimized for co" "Useful for when you need to answ" "Input should be a search query.",
# 검색 출력의 개수
max_results=3)
위와 같이 수정이 필요하다면 수정해 볼 수 있겠다.
노드를 구현하는 것은 앞선 코드를 똑같이 사용하였다.
실제로 바뀐 부분은 Bind한 툴의 이름만 바뀌었다.
##### STATE #####
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
class PersonaState(TypedDict):
user_input: str
messages: Annotated[list, add_messages]
character_persona_dict: dict
retrieve_check: bool
retrieval_msg: str
rewrite_query: str
##### NODE #####
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import HumanMessage, ToolMessage
character_model = ChatOpenAI(model="gpt-4o", temperature=0.2)
character_model_with_tools = character_model.bind_tools([tool])
def character_make_node(state: PersonaState):
prompt_with_tools = ChatPromptTemplate.from_messages([
("system","""
You are an expert in creating characters for fiction.\n
Whatever input the user is presented with, you must return a description of the completed character.\n
If no information is available, randomly generate and return the character's attributes.\n
Based on the values entered by the user, envision and present the character, including the character's age, gender, job, location, interests, hobbies and etc.\n
If you have difficulty creating an appropriate character, use an online search to solve the problem.\n
The returned value must be in Korean.\n
"""),
("human", "Input: {human_input}\n Retrieve: {context}"),
])
# 이전에도 설명했듯 state의 add_messages 함수는 계속해서 뒤로 메세지를 추가하는 형식
# Tool은 사용된 뒤 ToolMessage를 반환하는데, 이것이 add_message를 통해 뒤에 삽입됨
# 따라서 Tool이 제공한 값을 사용하기 위해서는 state의 messages속 가장 마지막 인자를 받아야 함.
# 다만 이러한 경우 마지막 메세지가 HumanMessage일 가능성도 있으므로, 이를 검증하고 진행.
messages_list = state['messages']
last_human_message = next((msg for msg in reversed(messages_list) if isinstance(msg, HumanMessage)), None).content
last_msg = state['messages'][-1].content
# 이전 메세지 속 ToolMessage가 없는 경우
if last_human_message == last_msg:
last_msg = ""
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}")
# 이전 메세지 속 ToolMessage가 있는 경우
# 이 경우 받아온 tool message의 content가 str 형식인 경우가 있어, json으로 변환
else:
try:
last_msg_data = json.loads(state['messages'][-1].content)
last_msg = "\n\n".join([d["content"] for d in last_msg_data])
except:
...
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}\nContext: {last_msg}")
chain_with_tools = prompt_with_tools | character_model_with_tools
response = chain_with_tools.invoke({"human_input": last_human_message, "context": last_msg})
# Tool을 호출하는 경우 AI는 빈 str과 tool_calls인자를 반환하게 된다.
# 즉 content = ""이 반환되고, tool_calls에는 호출한 Tool과 관련된 정보가 담겨 있다.
# 이를 검증하여 어떠한 Tool이 호출되었는지 표지할 수 있다.
if hasattr(response, "tool_calls") and len(response.tool_calls) > 0 and (response.tool_calls[0]["name"]) == "tavily_search_results_json":
print("=============================== Search Retrieval ===============================")
else:
print("============================= Chracter Information =============================")
print(response.content)
return {"messages": [response], "user_input": last_human_message}
##### EDGE #####
def simple_route(state: PersonaState):
"""
Simplery Route
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
# 만약 주어진 AIMessage에 검색 기능 호출이 존재한다면, 'tools'를 반환
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0 and ai_message.tool_calls[0]["name"] == "tavily_search_results_json":
print("Tavily Search Call")
return "tools"
# 아닌 경우 'next'를 반환
return "next"
# 반환된 값에 따라 어떤 노드로 이동할지를 결정하는 것.
graph_builder.add_conditional_edges(
"Character Make",
simple_route,
{"next": "Persona Setup", "tools": "Search Tool"}
)
코드는 매우 길지만 실제로 구현에 필요한 것은 많지 않다.
구현의 핵심만 기억하도록 하자.
- Tool을 정의한 뒤, 이것을 사용할 LLM에 Bind
- Tool이 호출되었을 때, 이를 받아줄 routing 함수와 conditional edge의 구현
- Tool의 Return을 받아(ToolMessage)이를 활용할 수 있는 Node의 구현
실제로 1번과 2번은 매우 간단하게 구현이 가능하므로
LangChain을 이용하여 ToolMesaage를 Context에 결합하는 것이 가장 중요하다고 볼 수 있겠다.
본 코드에서는, state['messages'] 속 마지막 HumanMessage와 마지막 Message를 비교하는 방식으로 이를 구현하였다.
3. 이제 모두 합치자! RAG + Tavily Search + 검증 Node
이제 모두 합칠 시간이다!
3번 포스팅에서 구현해 보았던 검증 Node와 함께 RAG 및 Tavily Search 기능을 한 번에 구현하도록 하자.
코드를 보는 것은 매우 복잡하지만, 단계적으로 구현한다면 크게 어렵지는 않다.
여기서 핵심은 2가지의 Tool을 Bind하는 것과
해당 Tool을 적절하게 routing 하는 것에 달려있다.
또한 Tool이 재귀적으로 반복 호출되는 것도 좋겠지만, 이런 경우 무한 루프에 빠질 수 있다.
때문에 본 포스팅에서는, tool_calls를 switch하는 boolean 형태의 state를 만들어 이를 방지하였다.
천천히 살펴보자.
##### STATE #####
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
class PersonaState(TypedDict):
user_input: str
messages: Annotated[list, add_messages]
character_persona_dict: dict
retrieve_check: bool
retrieval_msg: str
rewrite_query: str
tools_call_switch: Annotated[bool, True]
먼저 State를 정의한다.
여기서 tools_call_switch라는 새로운 state를 추가하였다.
** Annotated를 이용하여 기본값을 True로 사용하고 싶은데 제대로 작동하지 않는 것으로 보인다.
# 필요한 라이브러리를 한 번에 모두 로드
import os
import json
from .states import *
from pydantic import BaseModel, Field
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_core.messages import HumanMessage, ToolMessage
from langgraph.prebuilt import ToolNode
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.tools.retriever import create_retriever_tool
# API 키를 설정
with open('./api_key/API_KEY.txt', 'r') as api:
os.environ["OPENAI_API_KEY"] = api.read()
with open('./api_key/TAVILY_API.txt', 'r') as api:
os.environ["TAVILY_API_KEY"] = api.read()
# ChromaDB 로드
vectorstore = Chroma(
collection_name="rag-chroma",
embedding_function=OpenAIEmbeddings(),
persist_directory="./chroma_db",
)
retriever = vectorstore.as_retriever()
# tool의 경우 llm에 bind 용도로 사용할 것이고
tool = TavilySearchResults(max_results=3)
# web_search_tool의 경우 직접 invoke를 통해 검색 결과를 받아올 것이다.
# 해당 함수의 경우에는 재검색이 요청된 경우에 사용하도록 한다.
web_search_tool = TavilySearchResults(max_results=5)
# 노드 1-1. 검색용 노드
tool_node = ToolNode(tools=[tool])
# 검색용 RAG 툴 로드하고 노드만듦
retriever_tool = create_retriever_tool(
retriever,
"retrieve_trends",
"Search for the latest trends in fashion and hobbies and return relevant information.",
)
# 노드 1-2. RAG용 노드.
retrieve = ToolNode([retriever_tool])
# 두 개 툴 엮어서 리스트 만듦.
tools = [tool, retriever_tool]
다음으로는 라이브러리를 로드하고 아까와 마찬가지로 필요한 Tool 들을 정의하였다.
그리고 해당 Tool을 LangGraph의 ToolNode Class를 이용하여 Node로 만들어 주었다.
# 툴 2개가 bind된 character_make_node
character_model = ChatOpenAI(model="gpt-4o", temperature=0.2)
character_model_with_tools = character_model.bind_tools(tools)
def character_make_node(state: PersonaState):
prompt = ChatPromptTemplate.from_messages([
("system","""
You are an expert in creating characters for fiction.\n
Whatever input the user is presented with, you must return a description of the completed character.\n
If no information is available, randomly generate and return the character's attributes.\n
Based on the values entered by the user, envision and present the character, including the character's age, gender, job, location, interests, hobbies and etc.\n
The returned value must be in Korean.\n
"""),
("human", "Input: {human_input}\n Retrieve: {context}"),
])
prompt_with_tools = ChatPromptTemplate.from_messages([
("system","""
You are an expert in creating characters for fiction.\n
Whatever input the user is presented with, you must return a description of the completed character.\n
If no information is available, randomly generate and return the character's attributes.\n
Based on the values entered by the user, envision and present the character, including the character's age, gender, job, location, interests, hobbies and etc.\n
If you have difficulty creating an appropriate character, use an online search to solve the problem.\n
The returned value must be in Korean.\n
"""),
("human", "Input: {human_input}\n Retrieve: {context}"),
])
messages_list = state['messages']
last_human_message = next((msg for msg in reversed(messages_list) if isinstance(msg, HumanMessage)), None).content
last_msg = state['messages'][-1].content
if last_human_message == last_msg:
last_msg = ""
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}")
else:
try:
last_msg_data = json.loads(state['messages'][-1].content)
last_msg = "\n\n".join([d["content"] for d in last_msg_data])
except:
...
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}\nContext: {last_msg}")
if state['tools_call_switch']:
chain_with_tools = prompt_with_tools | character_model_with_tools
response = chain_with_tools.invoke({"human_input": last_human_message, "context": last_msg})
if hasattr(response, "tool_calls") and len(response.tool_calls) > 0 and (response.tool_calls[0]["name"]) == "tavily_search_results_json":
print("================================ Search Online ================================")
tool_switch = False
elif hasattr(response, "tool_calls") and len(response.tool_calls) > 0 and (response.tool_calls[0]["name"]) == "retrieve_trends":
print("=============================== Search Retrieval ===============================")
tool_switch = False
else:
print("============================= Chracter Information =============================")
tool_switch = False
print(response.content)
else:
chain = prompt | character_model
response = chain.invoke({"human_input": last_human_message, "context": last_msg})
print("============================= Chracter Information =============================")
tool_switch = False
print(response.content)
return {"messages": [response], "user_input": last_human_message, "tools_call_switch": tool_switch}
아까와 동일하지만 이번에는 2개의 Tool을 Binde하여 만들었다.
더불어 tools_call_switch라는 state를 함께 사용하기 때문에, 이를 처리하기 위해 2가지의 prompt를 사용하고 있다.
여기서 tools_call_switch는 처음 Input Node에 의해 True로 설정된 상태로 넘어오게 된다.
처음 character_make_node에 진입하게 되면, 해당 값이 True인 상태로 해당 노드를 통과하게 되지만
한 번 통과하고 난 이후에는 False로 변경되기 때문에, 이후에는 해당 노드에서 Tool 호출이 불가능하다.
이런 방식을 통해 Tool을 반복적으로 호출하지 못하도록 만든 것이다.
만약 1번이 아닌 3번으로 제한을 두고 싶다면, 이를 감지할 수 있는 index를 만들고
해당 노드를 통과할 때 마다, index의 값을 1씩 증가하게 만듦으로써 해당 index가 특정 수치 아래일 때만
노드가 Tool을 호출하도록 만들어 볼 수도 있을 것이다.
# 노드 1-3. RAG 검증노드
# 노드 1-2의 Tools Output을 받아서, User Input에 잘 맞는지 검증해서 Yes Or No로 대답함.
# 만약 Yes라면 그대로 다시 Character Make Node로 보내서 최종 답변을 생성하도록 하고
# 아니라면 검색을 진행하고 새로운 값을 받아서 보낼거임.
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score:str = Field(..., description="Documents are relevant to the question, 'yes' or 'no'", enum=['yes', 'no'])
rag_check_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
rag_check_model = rag_check_model.with_structured_output(GradeDocuments)
def retrieve_check_node(state: PersonaState):
prompt = ChatPromptTemplate.from_messages(
[
("system", """
You are a consultation expert who provides appropriate information in response to user input.
Return 'yes' or 'no' if you can provide an accurate answer to the user's question from the given documentation.
If you can't provide a clear answer, be sure to return NO.
"""),
("human", "Retrieved document: \n\n {document} \n\n User's input: {question}"),
]
)
retrieval_msg = state['messages'][-1].content
human_msg = state['user_input']
retrieval_grader = prompt | rag_check_model
response = retrieval_grader.invoke({"document": retrieval_msg, "question": human_msg})
retrieve_handle = response.binary_score
retrieve_check = False
if retrieve_handle == "no":
print("=============================== Need to Check ===============================")
retrieve_check = True
if retrieve_handle == "yes":
print("============================== No Need to Check =============================")
return {"retrieve_check": retrieve_check, "retrieval_msg": retrieval_msg}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1-4. 쿼리 재-작성 노드
# 노드 1-2에서 산출된 retrieve가 입력값과 적절하게 매치되지 않는 경우, 입력값을 수정하게 됨.
# state User_input 이용
# 이는 노드 1-3에서 yes를 반환하는 경우에 실행됨.
class Rewrite_Output(TypedDict):
"""
Sturctured_output을 생성하기위한 클래스
"""
query: Annotated[str, ..., "Rewritten query to find appropriate material on the web"]
rewrite_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
rewrite_model = rewrite_model.with_structured_output(Rewrite_Output)
def rewrite_node(state: PersonaState):
prompt = ChatPromptTemplate.from_messages(
[
("system", """
You're an expert in improving search relevance.\n
Look at previously entered search queries and rewrite them to better find that information on the internet.
"""),
("human", "Previously entered search queries: \n{user_input}"),
]
)
user_input = state['user_input']
rewrite_chain = prompt | rewrite_model
response = rewrite_chain.invoke({"user_input": user_input})
rewrited_query = response['query']
print(f"================================ Rewrited Query ================================\nRewritted Query: {rewrited_query}")
return {"rewrite_query": rewrited_query}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1-5. 재작성된 쿼리를 이용해서 인터넷 검색하는 노드
def rewrite_search_node(state: PersonaState):
print("================================ Search Web ================================")
docs = web_search_tool.invoke({"query": state['rewrite_query']})
web_results = "\n\n".join([d["content"] for d in docs])
web_results = web_results + "\n\n" + state['retrieval_msg']
# print(web_results)
new_messages = [ToolMessage(content=web_results, tool_call_id="tavily_search_results_json")]
return {"messages": new_messages}
# 1-5 노드에 대한 설명
3번 포스팅에서 사용했던 LangChain의 기술들을 사용하여 다음과 같이 검증과 검색 노드를 만들었다.
이 때 검색 노드의, 재작성된 쿼리를 받아 invoke를 수행한다.
이후 해당 값들에서 url을 제거한 content 값만 이용하여 결합하도록 만들었다.
더불어 (LLM은 잘못되었다고 판단하였지만), 호출되었던 retrieval_msg또한 함께 결합하여 최종 context로 제시하고 있다.
이러한 값을 기대하고 있는 형식 (ToolMesaage)으로 만들어 messages 속에 담아, 원 노드로 돌려준다.
# 라우팅 함수를 수정해주자.
# 검색이 필요한 것인지, 아니면 RAG가 필요한 것인지 탐색!
def simple_route(state: PersonaState):
"""
Simplery Route Tools or Next or retrieve
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0 and ai_message.tool_calls[0]["name"] == "tavily_search_results_json":
# print("Tavily Search Tool Call")
return "tools"
elif hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0 and ai_message.tool_calls[0]["name"] == "retrieve_trends":
# print("Retrieve Call")
return "retrieve"
return "next"
# 여기서는 RAG가 괜찮은지 검증하여 반환.
def retrieve_route(state: PersonaState):
"""
RAG Need Check?
"""
if state['retrieve_check']:
return "rewrite"
return "return"
# 마지막으로 지금까지 만든 노드를 모두 넣어준다.
graph_builder.add_node("User Input", user_input_node)
graph_builder.add_node("Character Make", character_make_node)
graph_builder.add_node("Character Retrieve Check", retrieve_check_node)
graph_builder.add_node("Rewrite Tool", rewrite_node)
graph_builder.add_node("Rewrite-Search", rewrite_search_node)
graph_builder.add_node("Tavily Search Tool", tool_node)
graph_builder.add_node("RAG Tool", retrieve)
graph_builder.add_edge(START, "User Input")
graph_builder.add_edge("User Input", "Character Make")
graph_builder.add_edge("Tavily Search Tool", "Character Make")
graph_builder.add_edge("RAG Tool", "Character Retrieve Check")
graph_builder.add_edge("Rewrite Tool", "Rewrite-Search")
graph_builder.add_edge("Rewrite-Search", "Character Make")
graph_builder.add_conditional_edges(
"Character Make",
simple_route,
{"tools": "Tavily Search Tool", "next": "Persona Setup", "retrieve": "RAG Tool"}
)
graph_builder.add_conditional_edges(
"Character Retrieve Check",
retrieve_route,
{"rewrite": "Rewrite Tool", "return": "Character Make"}
)
마지막으로 Routing 함수를 다시 정의해주고
지금까지 만들었던 Node를 Edge로 모두 추가해주자.
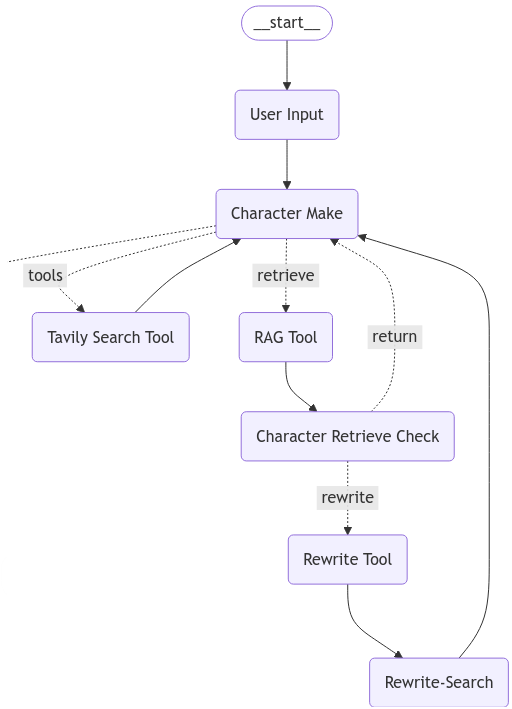
이렇게 하면 이번 시간의 목표인 위와 같은 Workflow를 모두 구현할 수 있게 된다.
여기서 Chracter Make 노드에서 Next가 반환되는 경우, 이전 포스팅에서 만들어 둔 Persona Setup으로 연결되도록 한다.
이렇게 하였을 때 전체 코드는 아래에 첨부해 두었다.
잘 작동한다!
LLM의 개별적인 기능을 단계적으로 엮는 것은 상당히 복잡한 과정이다.
그러나 LangGraph를 이용한다면, 개별 기능을 매우 순차적으로 엮어낼 수 있다.
LangGraph를 사용하며 느낀 것은 상당히 손쉽게 버그를 수정하고 기능을 구현할 수 있다는 것이다.
그래프 자체는 매우 거대해 보이지만 실제 구현 단계에서는 단계적으로 진행하게 되므로 크게 어려움이 없었다.
추후에는 이렇게 산출된 검색어를 이용하는 Agent 까지 설계해보자.
본문에 사용된 전체 코드
states.py / nodes.py / edges.py 세 가지로 나누어 관리하였음
######## states.py ########
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
class OverallState(TypedDict):
user_input: str
messages: Annotated[list, add_messages]
character_persona_dict: dict
class InputState(TypedDict):
start_input: str
class PersonaState(TypedDict):
user_input: str
messages: Annotated[list, add_messages]
character_persona_dict: dict
retrieve_check: bool
retrieval_msg: str
rewrite_query: str
tools_call_switch: Annotated[bool, True]
class SearchQueryState(TypedDict):
messages: Annotated[list, add_messages]
character_persona_dict: dict
query_list: list
previous_query: list
is_revise: bool
class EndState(TypedDict):
messages: Annotated[list, add_messages]
query_list: list
######## nodes.py ########
import os
import json
from .states import *
from pydantic import BaseModel, Field
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_core.messages import HumanMessage, ToolMessage
from langgraph.prebuilt import ToolNode
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.tools.retriever import create_retriever_tool
with open('./api_key/API_KEY.txt', 'r') as api:
os.environ["OPENAI_API_KEY"] = api.read()
with open('./api_key/TAVILY_API.txt', 'r') as api:
os.environ["TAVILY_API_KEY"] = api.read()
# ChromaDB 로드
vectorstore = Chroma(
collection_name="rag-chroma",
embedding_function=OpenAIEmbeddings(),
persist_directory="./chroma_db",
)
retriever = vectorstore.as_retriever()
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 시작노드 - 페르소나에 대한 정보를 요구하는 노드임
def user_input_node(state: InputState):
print("================================= Make Persona =================================")
print("페르소나를 결정합니다. 성별, 나이, 거주지, 취미 등 정보를 알려주세요.")
# time.sleep(1)
user_input = input("User: ")
return {"messages": [("user", user_input)], "tools_call_switch": True}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1 - 입력된 문장으로부터 새로운 페르소나를 만들어내는 노드.
# 검색용 Tavily 툴 로드하고 노드만듦.
tool = TavilySearchResults(max_results=3)
web_search_tool = TavilySearchResults(max_results=5)
# 노드 1-1. 검색용 노드
tool_node = ToolNode(tools=[tool])
# 검색용 RAG 툴 로드하고 노드만듦
retriever_tool = create_retriever_tool(
retriever,
"retrieve_trends",
"Search for the latest trends in fashion and hobbies and return relevant information.",
)
# 노드 1-2. RAG용 노드.
retrieve = ToolNode([retriever_tool])
def tool_nodes_exporter():
return tool_node, retrieve
# 두 개 툴 엮어서 리스트 만듦.
tools = [tool, retriever_tool]
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1-3. RAG 검증노드
# 노드 1-2의 Tools Output을 받아서, User Input에 잘 맞는지 검증해서 Yes Or No로 대답함.
# 만약 Yes라면 그대로 다시 Character Make Node로 보내서 최종 답변을 생성하도록 하고
# 아니라면 검색을 진행하고 새로운 값을 받아서 보낼거임.
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score:str = Field(..., description="Documents are relevant to the question, 'yes' or 'no'", enum=['yes', 'no'])
rag_check_model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
rag_check_model = rag_check_model.with_structured_output(GradeDocuments)
def retrieve_check_node(state: PersonaState):
prompt = ChatPromptTemplate.from_messages(
[
("system", """
You are a consultation expert who provides appropriate information in response to user input.
Return 'yes' or 'no' if you can provide an accurate answer to the user's question from the given documentation.
If you can't provide a clear answer, be sure to return NO.
"""),
("human", "Retrieved document: \n\n {document} \n\n User's input: {question}"),
]
)
retrieval_msg = state['messages'][-1].content
human_msg = state['user_input']
retrieval_grader = prompt | rag_check_model
response = retrieval_grader.invoke({"document": retrieval_msg, "question": human_msg})
retrieve_handle = response.binary_score
retrieve_check = False
if retrieve_handle == "no":
print("=============================== Need to Check ===============================")
retrieve_check = True
if retrieve_handle == "yes":
print("============================== No Need to Check =============================")
return {"retrieve_check": retrieve_check, "retrieval_msg": retrieval_msg}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1-4. 쿼리 재-작성 노드
# 노드 1-2에서 산출된 retrieve가 입력값과 적절하게 매치되지 않는 경우, 입력값을 수정하게 됨.
# state User_input 이용
# 이는 노드 1-3에서 yes를 반환하는 경우에 실행됨.
class Rewrite_Output(TypedDict):
"""
Sturctured_output을 생성하기위한 클래스
"""
query: Annotated[str, ..., "Rewritten query to find appropriate material on the web"]
rewrite_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
rewrite_model = rewrite_model.with_structured_output(Rewrite_Output)
def rewrite_node(state: PersonaState):
prompt = ChatPromptTemplate.from_messages(
[
("system", """
You're an expert in improving search relevance.\n
Look at previously entered search queries and rewrite them to better find that information on the internet.
"""),
("human", "Previously entered search queries: \n{user_input}"),
]
)
user_input = state['user_input']
rewrite_chain = prompt | rewrite_model
response = rewrite_chain.invoke({"user_input": user_input})
rewrited_query = response['query']
print(f"================================ Rewrited Query ================================\nRewritted Query: {rewrited_query}")
return {"rewrite_query": rewrited_query}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1-5. 재작성된 쿼리를 이용해서 인터넷 검색하는 노드
def rewrite_search_node(state: PersonaState):
print("================================ Search Web ================================")
docs = web_search_tool.invoke({"query": state['rewrite_query']})
web_results = "\n\n".join([d["content"] for d in docs])
web_results = web_results + "\n\n" + state['retrieval_msg']
# print(web_results)
new_messages = [ToolMessage(content=web_results, tool_call_id="tavily_search_results_json")]
return {"messages": new_messages}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 1번 작성된 것.
# 인간 입력이랑 Retrieve를 받을 수 있는 놈임.
character_model = ChatOpenAI(model="gpt-4o", temperature=0.2)
character_model_with_tools = character_model.bind_tools(tools)
def character_make_node(state: PersonaState):
prompt = ChatPromptTemplate.from_messages([
("system","""
You are an expert in creating characters for fiction.\n
Whatever input the user is presented with, you must return a description of the completed character.\n
If no information is available, randomly generate and return the character's attributes.\n
Based on the values entered by the user, envision and present the character, including the character's age, gender, job, location, interests, hobbies and etc.\n
The returned value must be in Korean.\n
"""),
("human", "Input: {human_input}\n Retrieve: {context}"),
])
prompt_with_tools = ChatPromptTemplate.from_messages([
("system","""
You are an expert in creating characters for fiction.\n
Whatever input the user is presented with, you must return a description of the completed character.\n
If no information is available, randomly generate and return the character's attributes.\n
Based on the values entered by the user, envision and present the character, including the character's age, gender, job, location, interests, hobbies and etc.\n
If you have difficulty creating an appropriate character, use an online search to solve the problem.\n
The returned value must be in Korean.\n
"""),
("human", "Input: {human_input}\n Retrieve: {context}"),
])
messages_list = state['messages']
last_human_message = next((msg for msg in reversed(messages_list) if isinstance(msg, HumanMessage)), None).content
last_msg = state['messages'][-1].content
if last_human_message == last_msg:
last_msg = ""
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}")
else:
try:
last_msg_data = json.loads(state['messages'][-1].content)
last_msg = "\n\n".join([d["content"] for d in last_msg_data])
except:
...
print(f"==================================== INPUT ====================================\nHuman Input: {last_human_message}\nContext: {last_msg}")
if state['tools_call_switch']:
chain_with_tools = prompt_with_tools | character_model_with_tools
response = chain_with_tools.invoke({"human_input": last_human_message, "context": last_msg})
if hasattr(response, "tool_calls") and len(response.tool_calls) > 0 and (response.tool_calls[0]["name"]) == "tavily_search_results_json":
print("================================ Search Online ================================")
tool_switch = False
elif hasattr(response, "tool_calls") and len(response.tool_calls) > 0 and (response.tool_calls[0]["name"]) == "retrieve_trends":
print("=============================== Search Retrieval ===============================")
tool_switch = False
else:
print("============================= Chracter Information =============================")
tool_switch = False
print(response.content)
else:
chain = prompt | character_model
response = chain.invoke({"human_input": last_human_message, "context": last_msg})
print("============================= Chracter Information =============================")
tool_switch = False
print(response.content)
return {"messages": [response], "user_input": last_human_message, "tools_call_switch": tool_switch}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드2 - 입력된 문장으로부터 페르소나에 관한 정보를 추출하고, 정보가 없는 경우 이를 채워넣는 노드.
class Persona_Output(TypedDict):
"""
Sturctured_output을 생성하기위한 클래스
"""
character_age: Annotated[str, ..., "An age of the Persona"]
character_sex: Annotated[str, ..., "A sex of the Persona"]
character_location: Annotated[str, ..., "A place where the persona might live"]
character_interest: Annotated[str, ..., "Interests that the persona might have"]
character_hobby: Annotated[str, ..., "Hobbies that the persona might have"]
character_job: Annotated[str, ..., "Job that the persona might have"]
character_information: Annotated[str, ..., "Additional information to describe the persona"]
persona_model = ChatOpenAI(model="gpt-4o-mini", temperature=0.5)
persona_model = persona_model.with_structured_output(Persona_Output)
# 페르소나를 반환하는 매우 경직된 LLM.
# 정보가 없는 경우 임의의 값을 채워넣도록 되어있음.
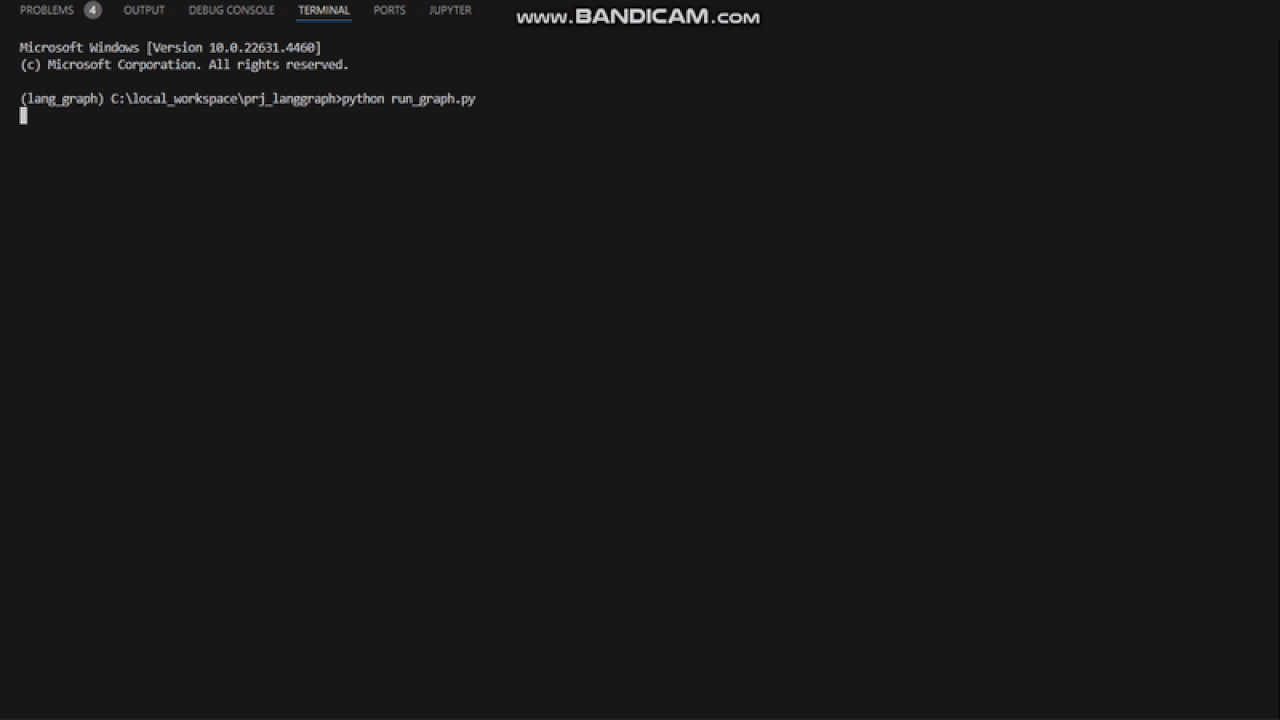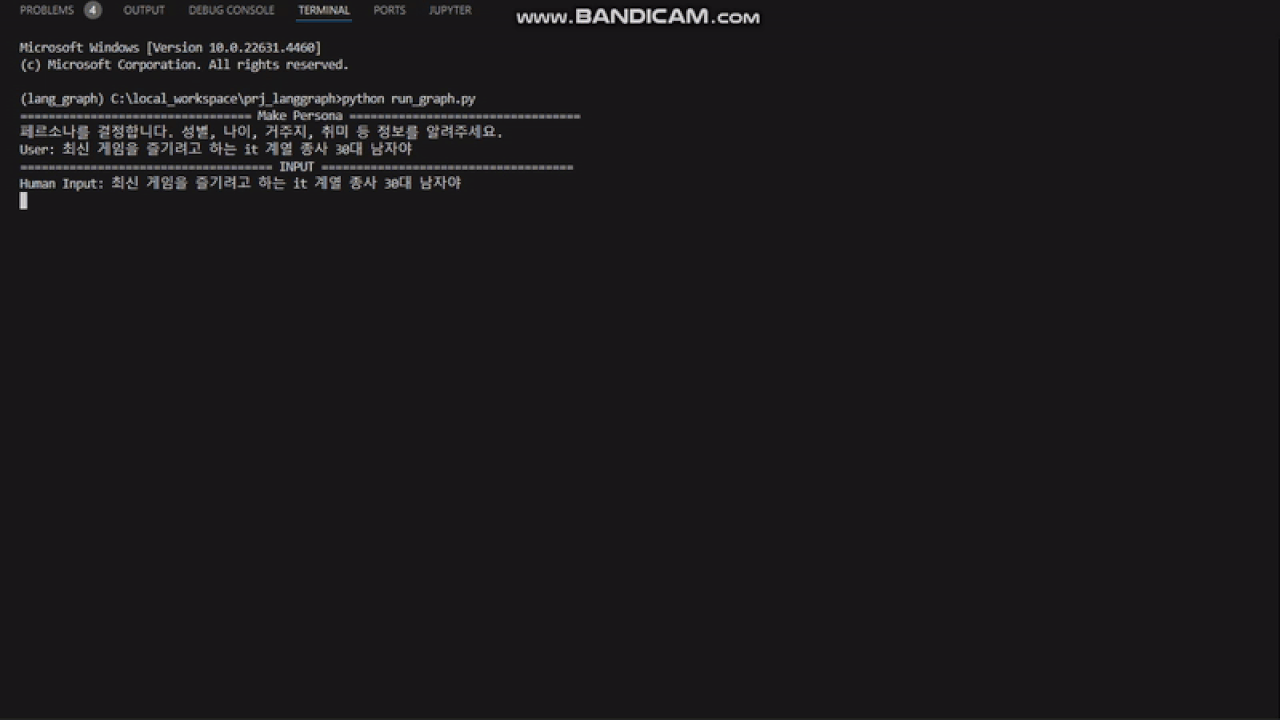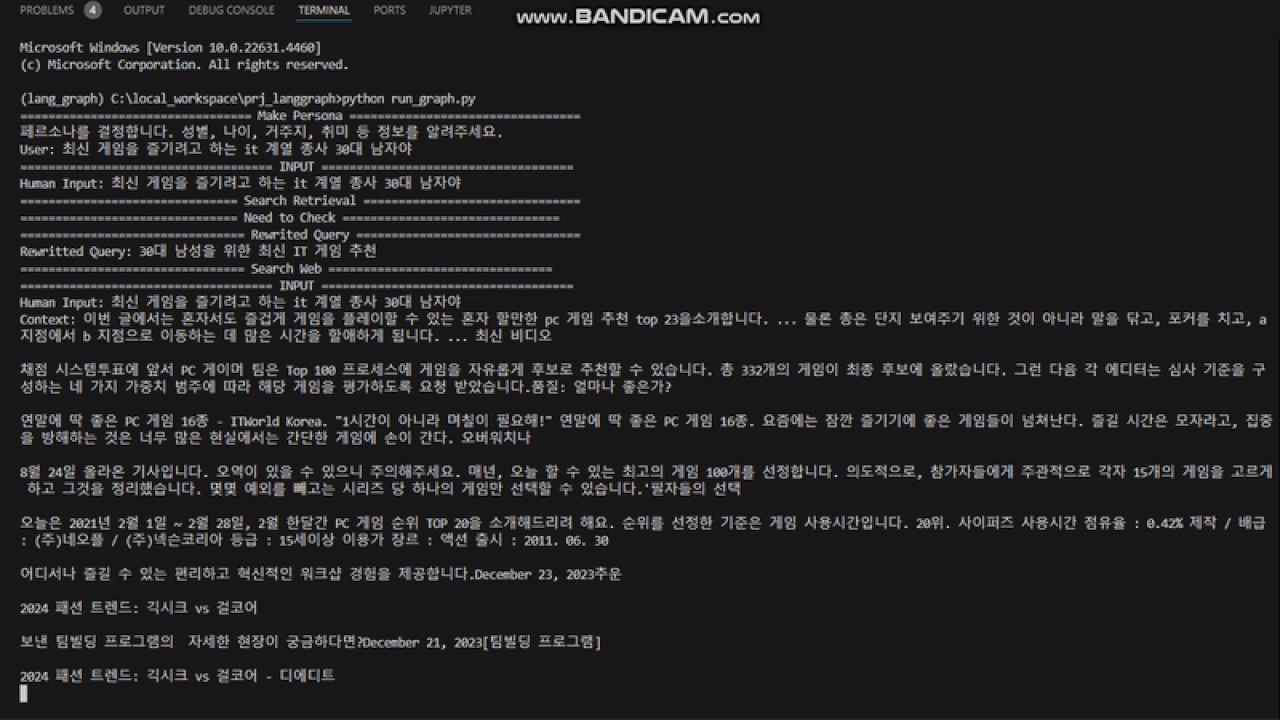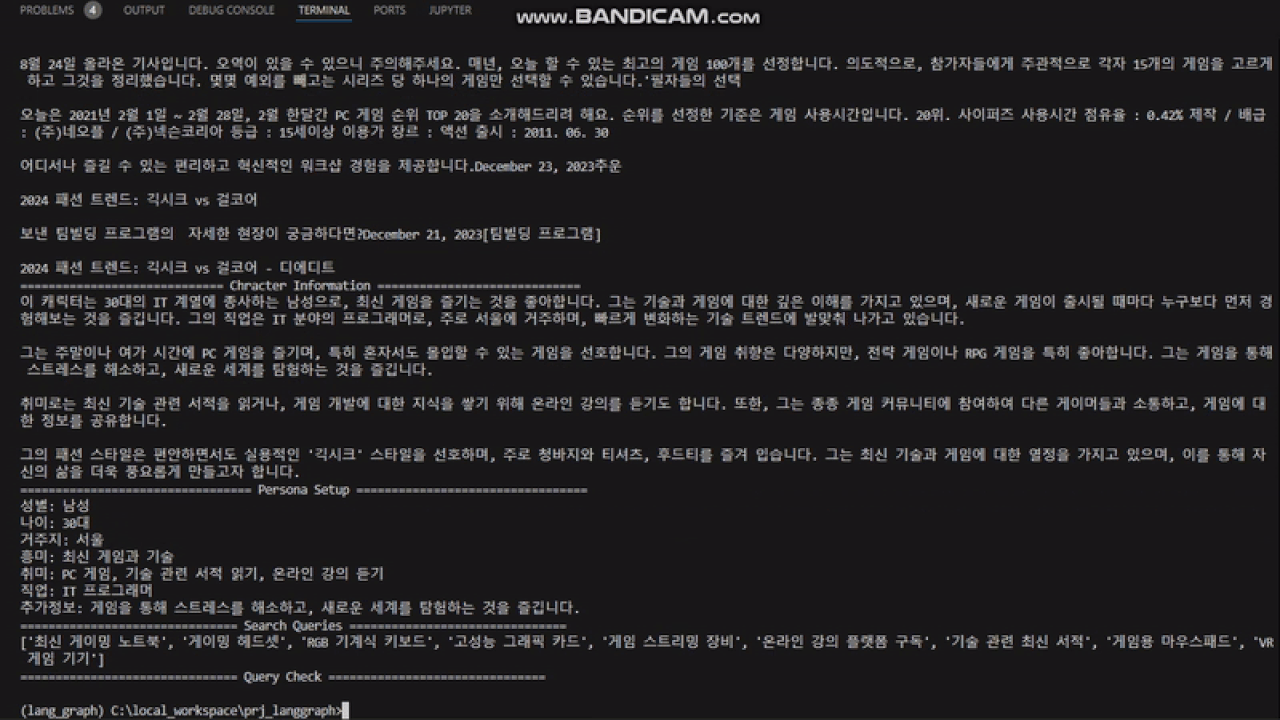
def persona_setup_node(state: PersonaState):
messages = [
("system", """
You are the expert in determining your character's persona.
Extract the character's 'age', 'sex', 'job', 'location', 'interest', and 'hobbies' from the values entered by the user.
If no information is available, it will return a randomised set of appropriate information that must be entered.
The returned value must be in Korean.
"""),
("human", state['messages'][-1].content)
]
response = persona_model.invoke(messages)
print("================================= Persona Setup =================================")
print(f"성별: {response['character_sex']}")
print(f"나이: {response['character_age']}")
print(f"거주지: {response['character_location']}")
print(f"흥미: {response['character_interest']}")
print(f"취미: {response['character_hobby']}")
print(f"직업: {response['character_job']}")
print(f"추가정보: {response['character_information']}")
return {"character_persona_dict": response}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 3 - 페르소나를 토대로 적절한 검색 키워드를 생성하는 놈.
class Search_Output(TypedDict):
"""
Sturctured_output을 생성하기위한 클래스
"""
query_list: Annotated[list, ..., "List of queries that customers have entered in your shop"]
search_model = ChatOpenAI(model="gpt-4o")
search_model = search_model.with_structured_output(Search_Output)
examples = [
{"input":
"""
User Sex: 여자,
User Age: 20대,
User Location: 서울 강남,
User Interest: 최신 화장법,
User Hobby: 공원 산책,
User Job: 그래픽 디자이너,
User Information: 강아지를 기르고 있음, 피부에 관심이 많음
""",
"output":
['피부진정용 필링패드', '수분에센스', '스틱형 파운데이션', '강아지 간식', '강아지용 배변패드', '강아지 장난감']
},
]
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
def search_setence_node(state: SearchQueryState):
prompt = ChatPromptTemplate.from_messages([
("system","""
You're a great marketing manager, and you're working on inferring customer search queries.
Given the customer information, generate appropriate search quries that customers might enter to find products in your shopping mall.
Make sure to clearly present the actual product names that a user with that persona would search for in your retail mall.
"""),
few_shot_prompt,
("human", """
User Sex: {sex},
User Age: {age},
User Location: {location},
User Interest: {interest},
User Hobby: {hobby},
User Job: {job},
User Information: {information}
"""),
])
chain = prompt | search_model
response = chain.invoke(
{
"sex": state['character_persona_dict']['character_sex'],
"age": state['character_persona_dict']['character_age'],
"location": state['character_persona_dict']['character_location'],
"interest": state['character_persona_dict']['character_interest'],
"hobby": state['character_persona_dict']['character_hobby'],
"job": state['character_persona_dict']['character_job'],
"information": state['character_persona_dict']['character_information'],
}
)
print("=============================== Search Queries ===============================")
print(response['query_list'])
return {"query_list": response}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 4, revise_tool - 반환된 서치쿼리가 적당한지 검증하는 노드임.
class QueryReviseAssistance(BaseModel):
"""Escalate the conversation.
Use only if the given search query is a strong mismatch with the customer's information.
Use this tool even if given search query is seriously inappropriate to enter into the search bar of an online retailer like Amazon.
Never call the tool if the same input is still being given as before.
To use this function, return 'query_list'.
"""
query_list: list
query_check_model = ChatOpenAI(model="gpt-4o", temperature=0.5, streaming=True)
query_check_model = query_check_model.bind_tools([QueryReviseAssistance])
def query_check_node(state: SearchQueryState):
print("=============================== Query Check ===============================")
prompt = ChatPromptTemplate.from_messages([
("system","""
You are a search manager.
If you think that the given customer's information and the search query that they used on your online store are relevant, then return the query as it is.
Never invoke the tool if you are still being given the same query that was entered in the previous dialogue.
"""),
("human", """
User Sex: {sex},
User Age: {age},
User Location: {location},
User Interest: {interest},
User Hobby: {hobby},
User Job: {job},
User Information: {information},
Queries: {queries}
"""),
])
chain = prompt | query_check_model
response = chain.invoke(
{
"sex": state['character_persona_dict']['character_sex'],
"age": state['character_persona_dict']['character_age'],
"location": state['character_persona_dict']['character_location'],
"interest": state['character_persona_dict']['character_interest'],
"hobby": state['character_persona_dict']['character_hobby'],
"job": state['character_persona_dict']['character_job'],
"information": state['character_persona_dict']['character_information'],
"queries": state['query_list']['query_list'],
}
)
is_revise = False
if (
response.tool_calls
and response.tool_calls[0]["name"] == QueryReviseAssistance.__name__
):
print("Revise Requires")
is_revise = True
return {"messages": [response], "is_revise": is_revise}
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# ----------------------------------------------------------------------------
# 노드 4-1. 쿼리를 수정하도록 요청받은 경우 이를 수행하는 노드임.
class QueryCheck_Output(TypedDict):
"""
Sturctured_output을 생성하기위한 클래스
"""
query_list: Annotated[list, ..., "List of queries that customers might have entered in search-bar of your online retail shop"]
query_revise_model = ChatOpenAI(model="gpt-4o")
query_revise_model = query_revise_model.with_structured_output(QueryCheck_Output)
def query_revise_node(state: SearchQueryState):
print("=============================== Query Revise ===============================")
prompt = ChatPromptTemplate.from_messages([
("system",
"""
You are a validator who fixes errors in a given query.
From the list of queries given, remove or modify the queries that do not match the user's information appropriately.
Be sure to delete highly irrelevant data.
Be sure to remove search terms that you wouldn't use on a shopping site like Amazon.
Return the modified queries as a list.
"""
),
("human",
"""
User Sex: {sex},
User Age: {age},
User Location: {location},
User Interest: {interest},
User Hobby: {hobby},
User Job: {job},
User Information: {information},
Queries: {queries}
"""
)])
chain = prompt | query_revise_model
response = chain.invoke(
{
"sex": state['character_persona_dict']['character_sex'],
"age": state['character_persona_dict']['character_age'],
"location": state['character_persona_dict']['character_location'],
"interest": state['character_persona_dict']['character_interest'],
"hobby": state['character_persona_dict']['character_hobby'],
"job": state['character_persona_dict']['character_job'],
"information": state['character_persona_dict']['character_information'],
"queries": state['query_list']['query_list'],
}
)
print(response['query_list'])
return {"query_list": response, "is_revise": False}
######## edges.py ########
from .states import *
from .nodes import *
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_community.tools.tavily_search import TavilySearchResults
# 라우팅을 위한 함수
def select_next_node(state: SearchQueryState):
if state["is_revise"]:
return "is_revise"
return '__end__'
def simple_route(state: PersonaState):
"""
Simplery Route Tools or Next or retrieve
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0 and ai_message.tool_calls[0]["name"] == "tavily_search_results_json":
# print("Tavily Search Tool Call")
return "tools"
elif hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0 and ai_message.tool_calls[0]["name"] == "retrieve_trends":
# print("Retrieve Call")
return "retrieve"
return "next"
def retrieve_route(state: PersonaState):
"""
RAG Need Check?
"""
if state['retrieve_check']:
return "rewrite"
return "return"
tool_node, retrieve = tool_nodes_exporter()
# 추가적인 필요사항 정리하고 그래프 빌딩
memory = MemorySaver()
graph_builder = StateGraph(OverallState, input=InputState, output=EndState)
graph_builder.add_node("User Input", user_input_node)
graph_builder.add_node("Character Make", character_make_node)
graph_builder.add_node("Character Retrieve Check", retrieve_check_node)
graph_builder.add_node("Rewrite Tool", rewrite_node)
graph_builder.add_node("Rewrite-Search", rewrite_search_node)
graph_builder.add_node("Persona Setup", persona_setup_node)
graph_builder.add_node("Search Sentence", search_setence_node)
graph_builder.add_node("Query Check", query_check_node)
graph_builder.add_node("Query Revise Tool", query_revise_node)
graph_builder.add_node("Tavily Search Tool", tool_node)
graph_builder.add_node("RAG Tool", retrieve)
graph_builder.add_edge(START, "User Input")
graph_builder.add_edge("User Input", "Character Make")
graph_builder.add_edge("Tavily Search Tool", "Character Make")
graph_builder.add_edge("RAG Tool", "Character Retrieve Check")
graph_builder.add_edge("Rewrite Tool", "Rewrite-Search")
graph_builder.add_edge("Rewrite-Search", "Character Make")
graph_builder.add_edge("Persona Setup", "Search Sentence")
graph_builder.add_edge("Search Sentence", "Query Check")
graph_builder.add_edge("Query Revise Tool", "Query Check")
graph_builder.add_conditional_edges(
"Query Check",
select_next_node,
{"is_revise": "Query Revise Tool", END: END}
)
graph_builder.add_conditional_edges(
"Character Make",
simple_route,
{"tools": "Tavily Search Tool", "next": "Persona Setup", "retrieve": "RAG Tool"}
)
graph_builder.add_conditional_edges(
"Character Retrieve Check",
retrieve_route,
{"rewrite": "Rewrite Tool", "return": "Character Make"}
)
##### edges.py에서 Graph Export #####
def Project_Graph():
graph = graph_builder.compile(checkpointer=memory)
return graph
####### run_graph.py #######
from .edges import Project_Graph
graph = Project_Graph()
config = {"configurable": {"thread_id": "1"}}
with open("graph_output.png", "wb") as f:
f.write(graph.get_graph().draw_mermaid_png())
graph.invoke({"start_input": ""}, config=config)



