관련 시리즈
- 2024.11.11 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 1. LangGrpah(랭그래프)를 이용한 AI Workflow 관리하기
- 2024.11.13 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 2. LangGrpah(랭그래프)의 핵심 요소의 개념적 이해 (현재글)
- 2024.11.14 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 3. Chain과 Agent를 이용한 Workflow 구현 - 쿼리 추출 모델
- 2024.11.20 - [A.I.(인공지능) & M.L.(머신러닝)/LLM] - [LangGrpah] 4. LangGraph를 이용한 RAG 및 검색 Agent 개발
이전 포스팅에서 LangGraph에 대해서 간단하게 살펴보았다.
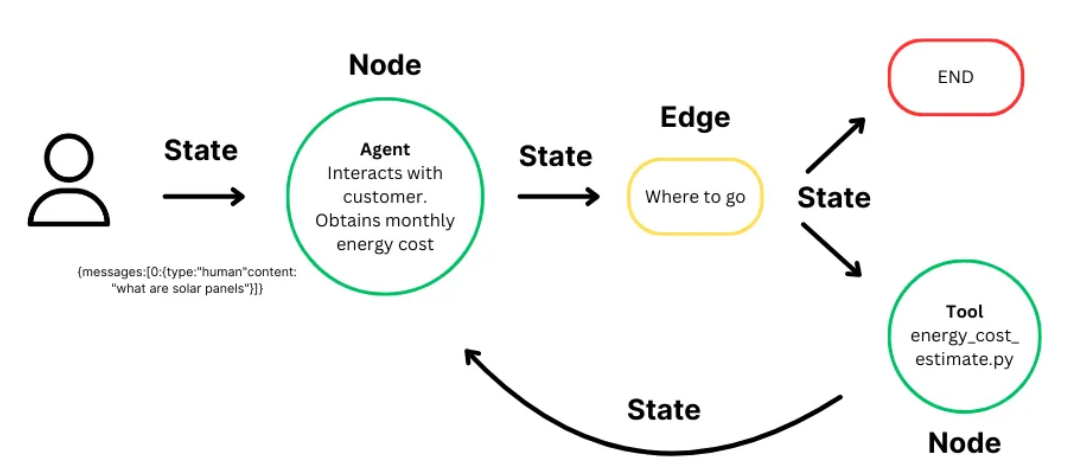
이번에는 LangGraph의 핵심 요소 3가지(State, Node, Edge)가 어떻게 동작하는지 이해하고자 한다.
추가적인 정보가 필요하다면 LangGraph 공식 Document에서 제공하는 튜토리얼을 참고하자(링크)
1. State
LangGraph는 기본적으로 다양한 도구(정확하게는 Node)들의 연결된 집합으로 이해할 수 있다.
여기서 도구는 [검색 엔진, 웹 드라이버, 거대 언어 모델] 등 범위가 한정되지 않고 다양하다.
이렇듯 다양한 도구가 하나의 Workflow에 얽혀있기 때문에
우리는 다양한 도구들이 공유할 수 있는 '전역적인 상태'가 필요하게 된다.
즉, 쉽게 생각한다면 State는 전역적인 변수를 관리하기 위한 공간인 것이다.
이렇게 때문에 Graph에 존재하는 모든 노드들은 바로 이 'State'를 통해 소통하게 된다.
class ExampleState(TypedDict):
x: int
y: float
sentence: str
queries: list
LangGraph에서는 이러한 State를 위와 같이 TypedDict를 통해 관리한다.
TypedDict는 Python 3.8 부터 지원되기 시작한 자료 형태로
기본적으로 Dictionary와 동일하지만 해당 변수들의 Type을 지정할 수 있다.
이러한 TypedDict의 변수들은 새롭게 할당될 때 마다 업데이트 되며
최종적인 변수들의 State에 따라 노드들이 특정한 작업을 수행하도록 지시할 수 있다.
요약하자면, State란
Node들의 소통하는 전역적인 변수라고 볼 수 있다.
2. Node
노드는 전체적인 Workflow의 기능적인 단위라고 생각할 수 있다.
아주 쉽게 이해한다면, 개별적인 기능을 담당하는 '함수'라고 생각할 수 있다.
즉 가장 간단하게 구현된 Node는 Python의 기본적인 함수와 다를 것이 없다.
예시를 한 번 살펴보자.
from typing_extensions import TypedDict
# State
class ExampleState(TypedDict):
number: int
# Node
def make_squered_node(state: ExampleState):
return {number: (state['number'])**2}
이렇듯 노드는 매우 간단하게 정의될 수 있다.
다만 LangGraph의 노드들이 가지고 있는 특징들에 대해서는 알아 둘 필요가 있다.
- make_squered_node는 ExampleState 형태의 'INPUT'을 요구한다.
- make_squered_node는 ExampleState에서 정의된 변수들에 접근할 수 있다.
- 이러한 변수 혹은 노드 내부에서 정의된 기능을 수행한 뒤, [다음 노드가 요구하는 형태]의 State를 반환한다.
즉, Graph 속의 모든 노드는 다음과 같이 State에서 정의한 기준을 토대로 연결되어 있으며
이를 토대로 명확하게 연결을 형성하는 것이 가장 중요하다고 볼 수 있다.
이는 곧 LangGraph의 최종적인 목표인 Agent의 Stable한 사용에 필수적이기 때문이다.
그렇다면 LangGraph에서 자주 사용되는 Annotated 문법에 대해 잠깐 살펴보자.
from typing import Annotated
name: Annotated[str, "이름"]
location: Annotated[str, "거주지"]
Annotated는 파이썬에서 제공되는 타입힌팅의 하나의 방법이다.
그러나 여기서는 단순하게 코드의 가독성을 증대시키는 역할로만 사용되는 것이 아니다.
LangChain 및 LangGraph에서는 Annotated를 사용하여
다양한 기능적 요소들을 구현하고 있기에 반드시 살펴보아야 한다.
대표적인 두 가지만 살펴보도록 하겠다.
# 1. messages의 관리
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
아까 살펴본 것과 같이 하나의 State를 정의하였다.
이번에 정의된 messages라는 변수는 add_messages라는 함수를 Annotated의 인자로 받고 있다.
이는 LangGraph에서 사용하는 특수한 형태로
User와 LLM의 messages를 add_messages라는 함수를 이용하여 관리하겠다는 이야기다.
여기서 add_messages 함수는 리스트로 된 Messages Type의 인자를 받아 병합하는 기능을 수행한다.
from langchain_core.messages import AIMessage, HumanMessage
from langgraph.graph import add_messages
msgs1 = [HumanMessage(content="Hello", id="1")]
msgs2 = [AIMessage(content="Hi there!", id="2")]
result = add_messages(msgs1, msgs2)
print(result)
# [HumanMessage(content='Hello', additional_kwargs={}, response_metadata={}, id='1'), AIMessage(content='Hi there!', additional_kwargs={}, response_metadata={}, id='2')]
LangGraph에서는 이러한 방식을 통해 사용자와 LLM 간 메세지의 흐름을 관리하고 있다.
다음으로 알아볼 것은 langchain에서 제공하는
with_structured_output을 사용하기 위한 Annotated의 사용이다.
아래의 코드를 살펴보자.
# 2. Annotated를 이용한 Structured Output 만들기
from typing_extensions import Annotated, TypedDict
from langchain_openai import ChatOpenAI
# TypedDict
class Joke(TypedDict):
"""Joke to tell user."""
# json형태의 parsing을 위해 아래와 같이 구성된다.
# key명칭: Annotated[value의 타입, 기본값, 설명]
setup: Annotated[str, ..., "The setup of the joke"]
punchline: Annotated[str, ..., "The punchline of the joke"]
rating: Annotated[Optional[int], None, "How funny the joke is, from 1 to 10"]
llm = ChatOpenAI(model="gpt-4o-mini")
structured_llm = llm.with_structured_output(Joke)
structured_llm.invoke("Tell me a joke about cats")
# Output:
{'setup': 'Why was the cat sitting on the computer?',
'punchline': 'Because it wanted to keep an eye on the mouse!',
'rating': 7}
매우 간단한 방식으로 TypedDict 형태의 class를 정의한 뒤
필요한 요소들을 위와 같은 형식에 맞추어 제공하면 끝이다.
이를 통해 LLM의 Output을 지정함으로써 매우 견고한 사용이 가능하게 된다.
3. Edge
다시 돌아와 Edge에 대해 알아보면
Edge는 기능적으로 보았을 때, State를 받아 State를 넘겨주는 역할을 수행한다
(기능적으로 보았을 때 간단한 라우팅을 수행하는 '노드'라고 보아도 무관할 것이다.)
일반적으로 단방향 연결에서는 특별하게 고려할 것이 없이, LangGraph가 알아서 잘 처리한다.
다만 조건이나 상태에 따라 다른 연결을 구현하고자 한다면 다음과 같이 구현이 가능하다.
from typing_extensions import TypedDict
from typing import Annotated
from langgraph.graph import StateGraph, START, END
# graph_builder를 통해 그래프의 요소들을 구성한다.
# 이후 예제에서 더 자세하게 살펴볼 것이니 일단 넘어가자.
graph_builder = StateGraph(State)
# 다음과 같이 ask_human이라는 전역적 변수가 추가된 State가 있다고 해보자.
class State(TypedDict):
messages: Annotated[list, add_messages]
ask_human: bool
# 만약 해당 변수가 True인 경우 "human"이라는 값을 반환한다.
# 아니라면 "next_node"라는 값을 반환한다.
def select_next_node(state: State):
if state["ask_human"]:
return "human"
return "next"
# add_conditional_edges는 graph_builder가 사용하는 함수 중 하나로
# 상태에 따라서 다른 노드로 연결되도록 한다.
# 여기서는 llm 이라는 노드에서 human_node 또는 next_node로 연결하도록 한다.
# 이것을 관리하는 라우팅은 앞서 정의한 select_next_node가 결정하는 것이다.
graph_builder.add_conditional_edges(
"llm",
select_next_node,
{"human": "human_node", "next": "next_node"}
)
간단하게 살펴보면 우리가 정의한 State 속 ask_human의 상태에 따라 다른 Node로 연결되게 된다.
여기서 파악해야하는 핵심은, 이전 Node에서 전달하는 특정 State가 라우팅의 '키' 가 된다는 것이다.
즉, 조건부 기능을 구현하고 싶다면 분기가 나뉘는 노드로부터 이를 선택할 수 있는 State를 조절해야 한다는 것이다.
이러한 핵심만 파악한다면 복잡한 구조라도 손쉽게 구현이 가능할 것이다.
이번 포스팅에서는 핵심 요소 3가지를 개념적으로 이해하고자 시도하였다.
요약하자면 다음과 같다.
1. State는 Graph의 전역적인 변수의 공간으로 Node간 통신, Edge에서의 라우팅 결정 등 다양한 요소에서 사용된다.
2. Node는 일종의 함수로 특정한 기능을 수행한 뒤 State를 업데이트하여 반환한다.
3. Edge는 간단한 라우팅을 수행하는 일종의 Node로, State를 입력받아 State를 전달하는 역할을 수행한다.
물론, 빠르고 쉬운 이해를 위해 생략되거나 손실된 정보가 존재할 수 있지만
LangGraph가 무엇인지 이해하기 위해서는 이 정도 수준으로 파악하고 있다면 충분하다고 생각한다.
다음 포스팅에서는 이러한 개념을 바탕으로 LLM과 Agent가 결합된 Graph를 구현해보도록 하겠다.
'A.I.(인공지능) & M.L.(머신러닝) > LLM' 카테고리의 다른 글
| [LangGrpah] 4. LangGraph를 이용한 RAG 및 검색 Agent 개발 (24) | 2024.11.20 |
|---|---|
| [LangGrpah] 3. Chain과 Agent를 이용한 Workflow 구현 - 쿼리 추출 모델 (0) | 2024.11.14 |
| [LangGrpah] 1. LangGrpah(랭그래프)를 이용한 AI Workflow 관리하기 (0) | 2024.11.11 |
| Adapting While Learning (2) | 2024.11.10 |
| Magentic-One : 새로운 Agent 프레임워크 (2) | 2024.11.10 |




