현재 LLM을 활용하는 방법은 주로 RAG를 기반으로 하는 Single Agent Architecture를 활용한다. 여기서 Agent란 LLM을 통상적으로 LLM을 하나의 지성체로 보고 스스로의 기억(Memory)를 기반으로 계획하고, 행동하고, 도구(Tools)를 사용하며 능동적으로 문제를 해결하는 하나의 존재 단위를 의미한다.
여행사에서 고객의 질문에 자동으로 답변하기 위해 FAQ를 바탕으로 Single Agent Architecture를 구축한다고 할 때
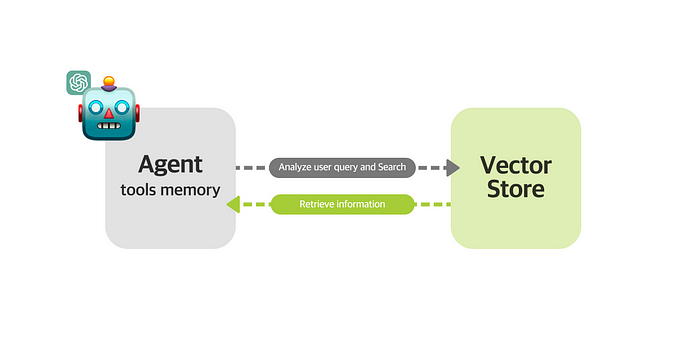
Single Agent Architecture를 통해 Agent는 사용자 질문에 대해 아래 단계를 거쳐 답변을 생성합니다.
- 사용자 질의를 분석하여 카테고리와 질문을 추출하고
- FAQ 데이터가 저장된 Vector Store에서 사용자 질문과 비슷한 QA 페어를 Search하고
- 마지막으로 해당 지식을 기반으로 LLM이 응답합니다.
그러나, Single Agent Architecture의 경우, 간단한 답변을 작성하는 것은 무리 없이 해결할 수 있지만 복잡한 질문을 하거나, 참고해야할 데이터의 수가 많고 Hallucination을 최소화해야하는 경우, 하나의 Agent만을 활용하는 것이 아니라 여러 Agent에게 역할을 부여하고
Agent 간의 협동을 통해 문제를 해결하는 Multi Agent Architecture를 도입할 필요가 있다
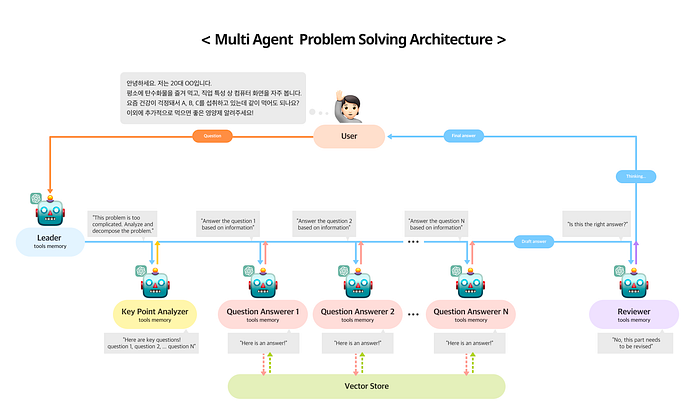
위는 Multi Agent Architecture 을 바탕으로 구성한 챗봇 시스템이다.
우선 고객이 질문을 했을 때 해당 질문에 대해서
1. Leader Agent가 질문을 중요한 key point에 따라서 몇가지로 분할해달라고 요청한다.
2. Leader Agent에 요청에 key point analyzer는 질문을 N개로 분할하고 분할된 질문을 Leader Agent는 Question Answerer에게 전달하여 각각의 분할된 질문에 대한 답을 Vector Store를 참조하여 한다.
3. 이렇게 얻어진 답을 Reviewer에게 전달하여 검토를 하고 검토 결과를 Leader Agent에게 전달하면 Leader Agent는 이를 정리하여 최종적인 답변을 고객에게 전달한다.
이런식으로 각각의 Agent의 역할을 부여하여 문제를 해결하는 프레임워크는 크게 Microsoft의 AutoGen과 Crew AI가 있다
AutoGen은 복잡한 작업을 위한 여러 Agents를 만들고 관리할 수 있도록 설계되었다. 이 도구는 특히 대화형 시스템과 관련된 프로젝트에서 유용한데, AutoGen을 사용하면 아래의 그림과 같이 다양한 역할을 하는 에이전트들을 구성하고, 이들 간의 상호작용을 관리하며, 그룹 채팅 시나리오를 구현할 수 있다.
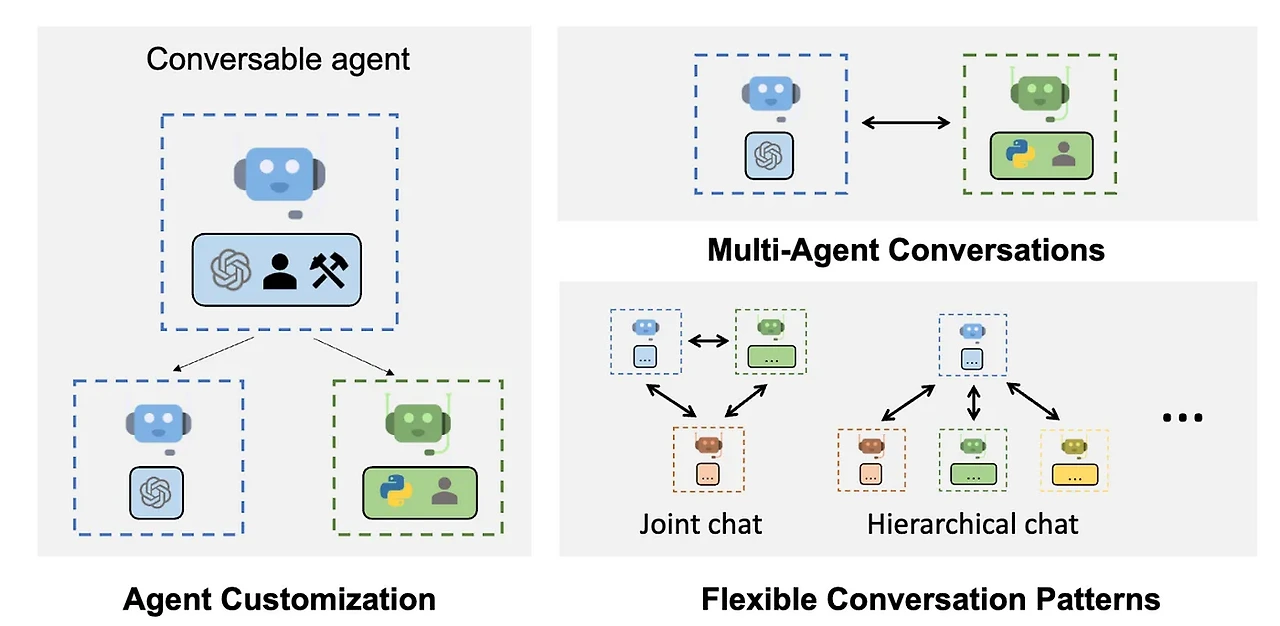
AutoGen의 장점은 다음과 같다.
1. 다중 에이전트 대화: 여러 에이전트가 협력하여 작업을 수행할 수 있도록 설계되었습니다. 이는 단일 LLM으로는 수행할 수 없는 복잡한 응용 프로그램을 가능하게 합니다.
2. 에이전트 커스터마이징: 에이전트를 사용자의 특정 요구에 맞게 커스터마이징할 수 있습니다. LLM 선택, 인간 입력 유형, 사용할 도구 등을 설정할 수 있습니다.
3. 인간 참여: AutoGen은 인간의 입력과 피드백을 에이전트 대화에 원활하게 통합할 수 있습니다. 이를 통해 에이전트의 신뢰성과 안전성을 향상시킬 수 있습니다.
4. 저코드 개발 환경: AutoGen Studio라는 저코드 인터페이스를 제공하여 개발자가 에이전트를 구성하고 워크플로우를 정의하며 테스트할 수 있습니다
Autogen 실제 사용 예시 (사용자와의 대화를 통한 개선)
pip install pyautogen
pip install vllm
python -m vllm.entrypoints.openai.api_server --model /MLP-KTLim/llama-3-Korean-Bllossom-8B --dtype auto --api-key token-abc123
import os
from autogen import AssistantAgent, UserProxyAgent
from autogen.coding import DockerCommandLineCodeExecutor
config_list = [{"model": "MLP-KTLim/llama-3-Korean-Bllossom-8B", "base_url" : "http://localhost:your_port/v1","api_key": "your_api_key"}]
# create an AssistantAgent instance named "assistant" with the LLM configuration.
assistant = AssistantAgent(name="assistant", llm_config={"config_list": config_list})
# create a UserProxyAgent instance named "user_proxy" with code execution on docker.
code_executor = DockerCommandLineCodeExecutor()
user_proxy = UserProxyAgent(name="user_proxy", code_execution_config={"executor": code_executor})
user_proxy.initiate_chat(
assistant,
message="""What date is today? Which big tech stock has the largest year-to-date gain this year? How much is the gain?""",
)Crew AI는 역할수행 가능한 인공지능 에이전트들이 서로 소통하고 협력하여 작업을 수행하는 프레임워크이며, 이를 통해 AI 협업이 가지는 다양한 장점을 최대한 활용할 수 있는데, Crew AI는 에이전트들에게 역할을 할당하고 공유 목표를 설정하며, 조화롭게 협력하는 방식으로 설계되었다.
Crew AI는 다음과 같은 장점을 가지고 있다:
1. 역할 기반 협업: 크루 AI는 에이전트들의 역할과 목표를 공유하여 협력을 장려하여 효율적으로 작업을 수행하고 문제를 해결한다.
2. 유연성과 확장성: 크루 AI는 다양한 에이전트와 태스크를 유연하게 조합하여, 복잡한 작업도 처리할 수 있으며, 필요에 따라 크루의 구성원을 추가하거나 변경할 수 있다.
3. 인공지능의 상호작용: 크루 AI는 에이전트 간의 상호작용을 통해 에이전트들은 서로의 작업 결과를 공유하고 조화롭게 협력하면서 문제를 해결한다.
단점은 다음과 같다.
1. 복잡한 구성: 크루 AI를 구성하는 에이전트들과 태스크를 설정하는 것은 조금 복잡할 수 있는데, 필요한 설정과 구성을 명확히 이해하고 적용해야 한다.
2. 학습 곡선: 크루 AI를 처음 사용하는 경우 학습 곡선이 존재할 수 있으며, 에이전트들 간의 상호작용과 작업 과정에서 발생할 수 있는 문제에 대한 이해와 대응이 필요하다.
Crew AI 실제 사용 예시
pip install 'crewai[tools]'
pip install vllm
python -m vllm.entrypoints.openai.api_server --model /MLP-KTLim/llama-3-Korean-Bllossom-8B --dtype auto --api-key token-abc123import os
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
#os.environ["SERPER_API_KEY"] = "Your Key" # serper.dev API key
# os.environ["SERPER_API_KEY"] = 'your SERPER_API_KEY'
# You can choose to use a local model through Ollama for example. See https://docs.crewai.com/how-to/LLM-Connections/ for more information.
os.environ["OPENAI_API_BASE"] = 'http://localhost:your_port/v1'
os.environ["OPENAI_MODEL_NAME"] ='/MLP-KTLim/llama-3-Korean-Bllossom-8B' # Adjust based on available model
os.environ["OPENAI_API_KEY"] ='sk-111111111111111111111111111111111111111111111111'
# You can pass an optional llm attribute specifying what model you wanna use.
# It can be a local model through Ollama / LM Studio or a remote
# model like OpenAI, Mistral, Antrophic or others (https://docs.crewai.com/how-to/LLM-Connections/)
#
# import os
# os.environ['OPENAI_MODEL_NAME'] = 'gpt-3.5-turbo'
#
# OR
#
# from langchain_openai import ChatOpenAI
search_tool = SerperDevTool()
# Define your agents with roles and goals
researcher = Agent(
role='Senior Research Analyst',
goal='Uncover cutting-edge developments in AI and data science',
backstory="""You work at a leading tech think tank.
Your expertise lies in identifying emerging trends.
You have a knack for dissecting complex data and presenting actionable insights.""",
verbose=True,
allow_delegation=False,
# You can pass an optional llm attribute specifying what model you wanna use.
# llm=ChatOpenAI(model_name="gpt-3.5", temperature=0.7),
tools=[search_tool]
)
writer = Agent(
role='Tech Content Strategist',
goal='Craft compelling content on tech advancements',
backstory="""You are a renowned Content Strategist, known for your insightful and engaging articles.
You transform complex concepts into compelling narratives.""",
verbose=True,
allow_delegation=True
)
# Create tasks for your agents
task1 = Task(
description="""Conduct a comprehensive analysis of the latest advancements in AI in 2024.
Identify key trends, breakthrough technologies, and potential industry impacts.""",
expected_output="Full analysis report in bullet points",
agent=researcher
)
task2 = Task(
description="""Using the insights provided, develop an engaging blog
post that highlights the most significant AI advancements.
Your post should be informative yet accessible, catering to a tech-savvy audience.
Make it sound cool, avoid complex words so it doesn't sound like AI.""",
expected_output="Full blog post of at least 4 paragraphs",
agent=writer
)
# Instantiate your crew with a sequential process
crew = Crew(
agents=[researcher, writer],
tasks=[task1, task2],
verbose=2, # You can set it to 1 or 2 to different logging levels
process = Process.sequential
)
# Get your crew to work!
result = crew.kickoff()
print("######################")
print(result)'A.I.(인공지능) & M.L.(머신러닝) > A.I. Information' 카테고리의 다른 글
| [AI] Hard Negatives 란? - reranker 학습에 필요한 DataSet (0) | 2025.01.06 |
|---|---|
| [이론] 검색 증강 생성 RAG(Retrieval-Augmented Generation) (0) | 2024.06.26 |
| [검색엔진] Vector Store (1) | 2024.06.03 |
| 인테리어 이미지 유사도 검색: 오늘의 집 (0) | 2024.05.16 |
| [이론] LLM GPU 학습 병렬처리 (DP, DDP, FSDP) (0) | 2024.04.18 |


