Topic. RAG 에 대해 알아봅니다.
1. RAG 란?
* 사전적 의미와 프로세스
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 프로세스입니다.

프로세스 내에서는 의도분류, 데이터 정합성판단, 환각현상 판단, 답변생성의 과정도 포함되어있습니다.
1-2. 종류
1-2-1. Adaptive RAG
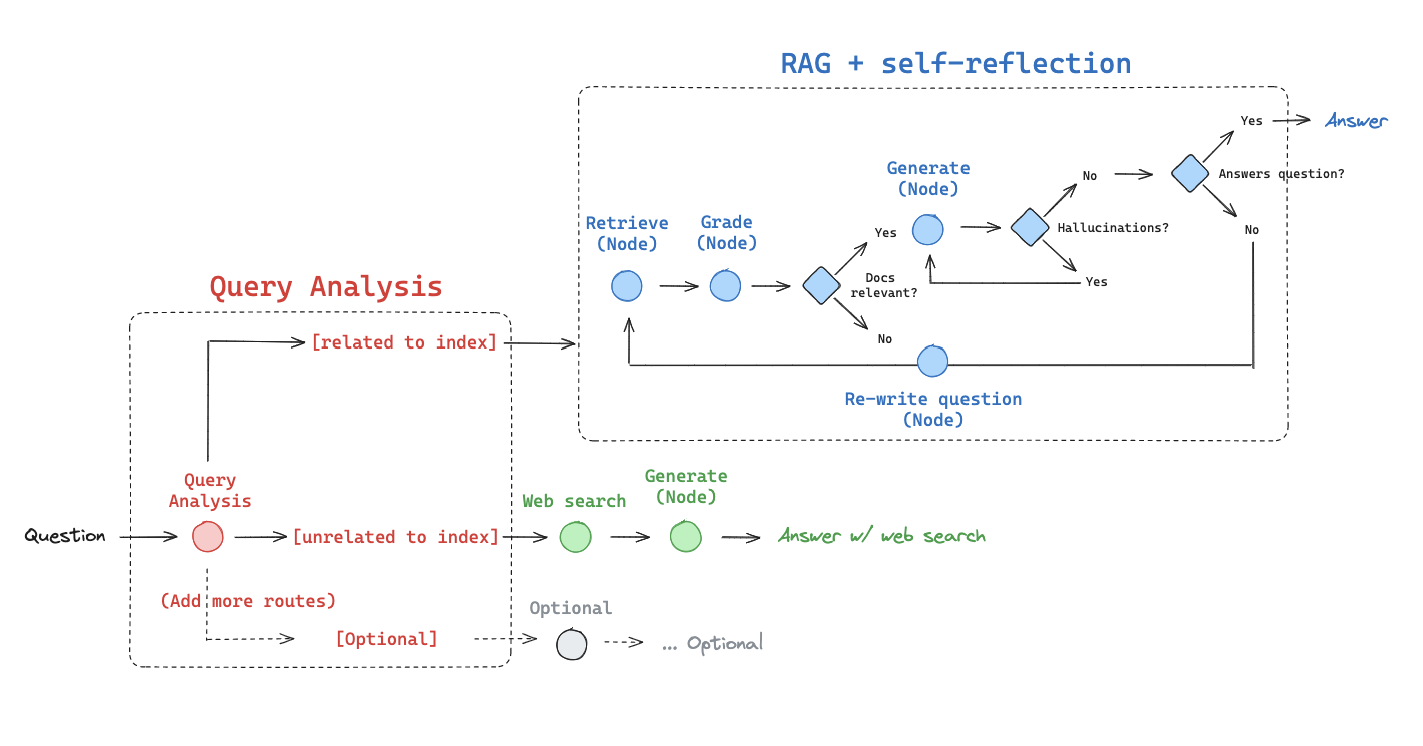
Adaptive RAG 는 사용자의 질문이 사용자가 가지고있는 데이터베이스의 정보와 연관성을 판단하여 검색어를 확장합니다. 연관성이 없을경우 검색엔진을 활용한 응답으로 넘어갑니다. 이는 검색엔진 뿐만 아니라 추가적인 데이터 수집 방법을 활용할 수 있습니다.
1-2-2. Corrective RAG (CRAG)
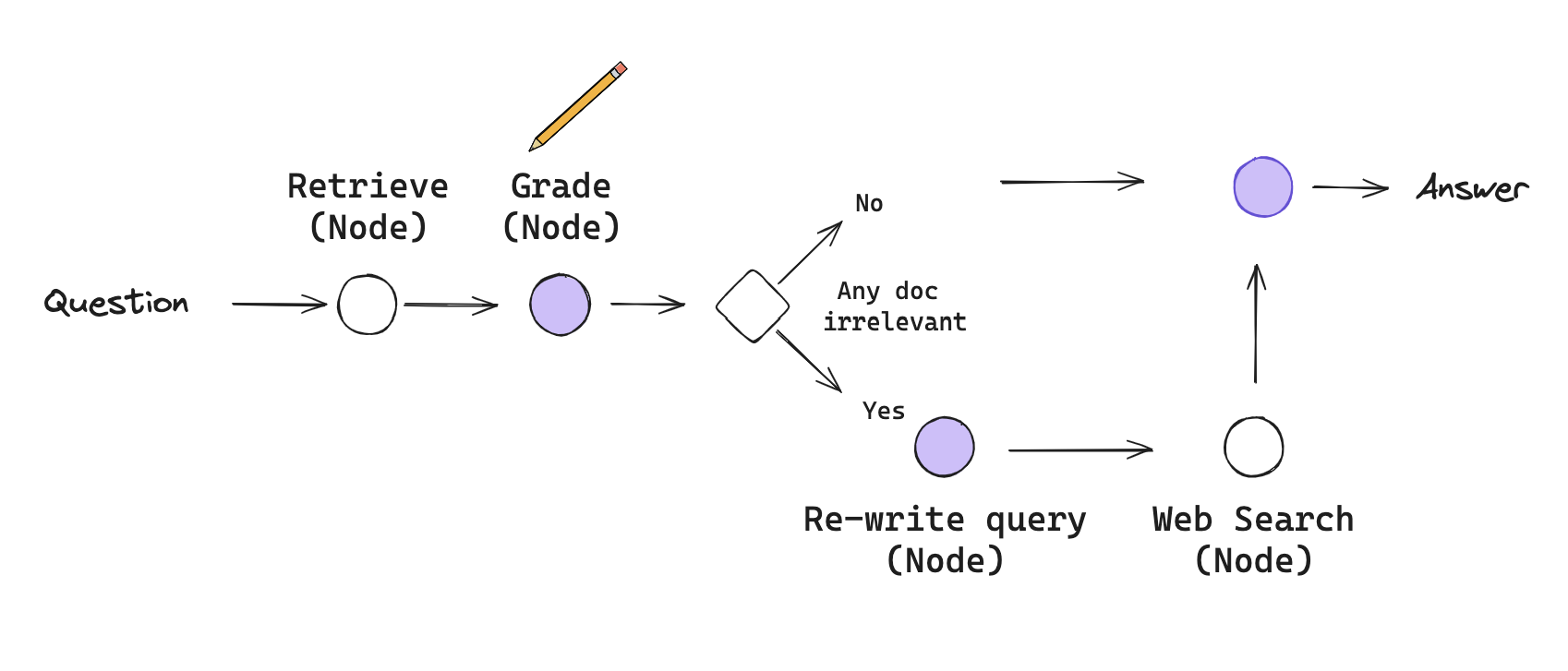
CRAG 는 Retrieval 된 검색어를 채점하는 RAG입니다. 채점시에 질문과 확장된 질문이 연관성이 없다면 쿼리를 재생성하고 검색엔진에 넣어 응답을 생성합니다.
1-2-3. Self_RAG
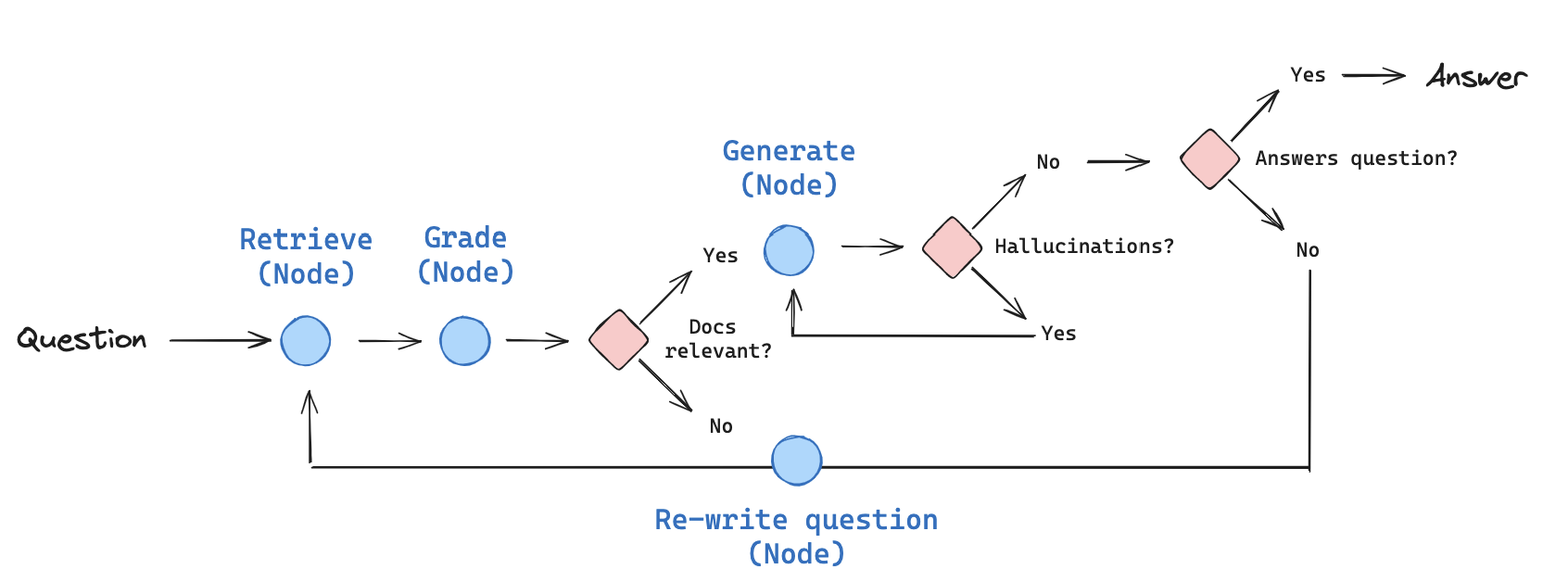
Self_RAG 는 질문을 증강하여 채점후 연관성이 없으면 질문을 다시 생성하여 연관성이 있을때까지 반복합니다.
1-3. 핵심 로직
RAG의 핵심 로직은 반복 쿼리 로직입니다. RAG 공식 문서에서는 langgraph의 StateGraph 를 활용하여 workflow를 생성합니다.
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# 노드 정의
workflow.add_node("web_search", web_search) # 검색엔진
workflow.add_node("retrieve", retrieve) # retrieve # 검색증강
workflow.add_node("grade_documents", grade_documents) # 검증
workflow.add_node("generate", generate) # Generate
workflow.add_node("transform_query", transform_query) # 질문 변형, 재생성
...2. 사용성
2-1. 실시간 학습 불가
현재 파라미터수가 엄청나게 거대해진 LLM 모델들이 데이터를 한건한건 실시간으로 학습하는것은 불가능 하다고 볼 수 있습니다. GPT-4o는 2023년 4월까지 의 데이터를 학습했으며 그 이후의 데이터는 알지 못합니다. 여러 새로운 문화와 지식이 급증하는 시기에 1년 이상의 지식차이는 아주 뒤떨어지는것으로 볼 수 있으며 이를 해결하기 위하여 프롬프트에 현재 데이터를 함께 넘겨주는 방법을 사용하기 시작했습니다. 이를 정형화하는 과정 중 RAG 방법론이 탄생했습니다.

2-2. Hallucination, 생성내용에 대한 피드백
실시간 학습이 불가하기에 LLM은 학습하지 않은 데이터에 대한 질문은 없는 지식을 새로 창조하거나 현실적이지 않은 말도 안되는 결과물로 답을 했습니다. 이는 정확한 정보를 요구하는 사용자에게는 아주 쓸모없는 인공지능이 될 것입니다. RAG 방법론에서는 자체적으로 LLM이 생성한 결과물이 현실적인지를 검증합니다.
'A.I.(인공지능) & M.L.(머신러닝) > A.I. Information' 카테고리의 다른 글
| [AI] Hard Negatives 란? - reranker 학습에 필요한 DataSet (0) | 2025.01.06 |
|---|---|
| Multi Agent LLM (0) | 2024.07.11 |
| [검색엔진] Vector Store (1) | 2024.06.03 |
| 인테리어 이미지 유사도 검색: 오늘의 집 (0) | 2024.05.16 |
| [이론] LLM GPU 학습 병렬처리 (DP, DDP, FSDP) (0) | 2024.04.18 |


