

Elasticsearch란?
검색엔진의 시초인 루씬 (Lucene)을 기반으로 하고 있으며, 비정형 데이터를 색인하고 검색하는 것이 가능하며, 장점 중 하나인 역색인 구조를 사용하므로써 빠른 검색이 가능하다.
Elasticsearch 기본 용어
| 용어 | 설명 |
| Index | 관계형 데이터베이스에서 table과 같이 데이터를 저장하는 공간 |
| Shard | 관계형 데이터베이스의 파티션과 같이 인덱스 내부에 색인된 데이터는 여러개의 파티션으로 구성 |
| Document | 관계형 데이터베이스의 row와 같이 데이터가 저장되는 최소 단위( JSON 포맷으로 저장) |
| Field | 관계형 데이터베이스의 Column과 같이 문서를 구성하기 위한 속성 |
| Mapping | 문서의 필드, 필드 속성을 정의하고 색인 방법을 정의 |
Elasticsearch의 장단점
장점
- 오픈 소스 검색 엔진 : 아파치 재단의 루씬 (Lucene) 기반으로 개발된 오픈 소스 검색엔진이며, 활발한 커뮤니티로 끊임 없이 개선되고 발전되고 있다.
- 역색인 : 역색인 구조로 전체 문서가 아닌 단어가 포함된 특정 문서의 위치를 알아내어 빠른 결과를 찾을 수 있다.
- 통계분석 : 비정형 로그 데이터를 수집하여 통계 분석에 활용할 수 있으며, Kibana를 연결하면 실시간으로 로그를 분석하고 시각화할 수 있다.
- Restful API : HTTP기반의 RESTful를 활용하고 요청/응답에 JSON을 사용해 개발 언어, 운영체제, 시스템에 관계없이 다양한 플랫폼에서 활용이 가능하다.
- Multi-teneancy : 서로 상이한 인덱스일지라도 검색할 필드명만 같으면 여러 인덱스를 한번에 조회할 수 있다.
- 다양한 검색 : 불린 검색, 언어 분석, 지리적 위치 검색, 쿼리 문자열, 맞춤법 검사 등 다양한 검색 기능을 제공한다.
단점
- Near Real-Time : 데 이터 저장 시점에 해당 데이터를 색인, 색인된 데이터는 1초 뒤에나 검색이 가능해져서 실시간으로 검색이 불가능하다. (내부적으로 커밋(commit), 플러쉬(Flush)와 같은 복잡한 과정을 거친다.)
- Transaction Rollback 지원 X : 전체적인 클러스터의 성능 향상을 위해 비용 소모가 큰 롤백과 트랜잭션 기능이 없다.
- 데이터 업데이트 X : 업데이트 명령이 올 경우 기존 문서를 삭제하고 새로운 문서를 생성한다. 업데이트에 비해서 많은 비용이 들지만 이를 통해 불변성(Immutable)이라는 이점을 취한다.
Elasticsearch의 알고리즘
Elasticsearch 기본 알고리즘이 TF/IDF에서 BM25로 바뀌면서 Elasticsearch 또한 5.0버전 이후부터 기본 유사도 알고리즘이 BM25로 사용되고 있다.
TF/IDF
TF (Term Frequency) - 단어 빈도
TF는 특정 문서에서 단어가 등장한 횟수를 말한다.
DF - 문서 빈도
DF는 특정 단어가 등장한 문서의 수를 말한다.
IDF (Inverse Document Frequency) - 역 문서 빈도
DF에 반비례하는 수를 뜻한다.
BM25
추천에 많이 사용되는 알고리즘으로 TF/IDF의 개념에 문서 길이를 고려한 알고리즘이다.
아래의 수식을 자세히 보면 TF/IDF의 계산에서 각각의 수식에 파라미터를 더하는 등 보정하여 성능이 개선되었다.
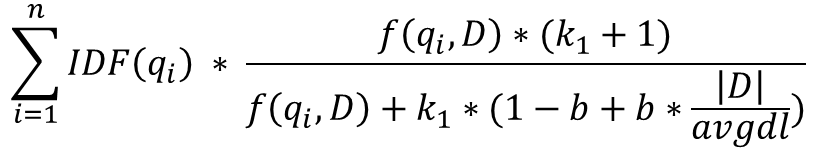
'Tech 공유 세미나 - 2차' 카테고리의 다른 글
| 3장. 검색 속도 비교와 형태소 분석 (0) | 2023.11.21 |
|---|---|
| 2장. 필드 타입 및 조회 방법 (0) | 2023.11.21 |
| 3장 플래티어의 구독형 DataLake 구축과 데이터 수집 전략 (0) | 2023.11.20 |
| 2장 Apache NiFi 활용 사례와 데모 (0) | 2023.11.20 |
| 1장 Apache NiFi 소개 (0) | 2023.11.20 |




