
루씬 (Lucene) 의 기본 알고리즘이 TF/IDF에서 BM25로 바뀌면서 Elasticsearch 또한 5.0버전 이후부터 기본 유사도 알고리즘이 BM25로 바뀌었다. 오늘은 TF/IDF 알고리즘과 현재 엘라스틱서치에서 사용되고 있는 BM25 알고리즘에 대해 정리하려고 한다.
BM25
우선 기본 BM25의 수식을 보자면
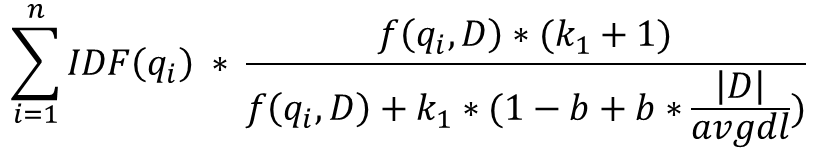
위와 같다.
...
...
...

TF/IDF 먼저 알아보도록 하자.
TF/IDF
TF/IDF는 단어가 얼마나 반복되는지, 얼마나 자주 사용되는지가 점수에 영향을 미친다. 하나의 문서에서 단어가 여러번 반복되면 점수가 높아지지만 전체 문서에서 단어가 자주 반복된다면 점수가 낮아지게 된다.
TF - 단어 빈도
TF는 특정 문서에서 단어가 등장한 횟수를 말한다. 문서에서 특정 단어가 자주 등장할수록 중요한 의미가 있다고 접근하여 점수를 반영한다.
IDF(d, t) - 역 문서 빈도
DF는 특정 단어가 등장한 문서의 수를 말한다. 문서에서 자주 등장한것과 상관 없이 등장했던 문서의 수를 뜻하여 문서에 자주 등장하는 단어는 점수를 낮게 반영한다. 즉, 대명사(저, 그, 이것, 저것...), 조사, 접속사(그리고, 그러나...) 등 어느 문서에나 출현 빈도가 높게 나오는 단어는 점수가 낮다는 뜻이다.
DF에 반비례하는 수를 뜻한다.
IDF의 수식은 다음과 같다.
- d : 문서
- t : 단어
- n : 총개수
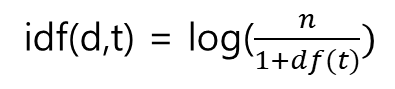
분모에 1을 더해 0이 되는 것을 방지하고, 로그를 취함으로써 값을 보정한다.
TF/IDF는 TF와 IDF를 곱한값이다.
BM25
이제다시 BM25에 대해 알아보자.
BM25는 검색, 추천에 많이 사용되는 알고리즘으로 TF/IDF의 개념에 문서 길이를 고려한 알고리즘이다.
위에 나왔던 수식을 자세히 보면 TF/IDF의 계산에서 각각의 수식에 파라미터를 더하는 등 보정하여 성능이 개선되었다.
- f(qi,D) = 문서에 매칭된 키워드 수
- k1 = 매개변수로 elasticsearch default는 1.2( tf를 위한 가중치)
- b = 매개변수로 elasticsearch default는 0.75 (길이의 가중치)
- |D| = 문서의 길이
즉, 문서의 검색어 빈도수가 같을때 문서의 길이가 길수록 낮은 점수를 주고, 잘 등장하지 않는 단어가 등장하면 높은 점수를 준다고 볼 수 있다.
'검색엔진 > Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] 형태소 분석과 검색 속도 비교 (0) | 2023.11.29 |
|---|---|
| [Elasticsearch] Elasticsearch 검색 방법(Query DSL) (1) | 2023.11.17 |
| [Elasticsearch] Elasticsearch 필드 데이터 타입 (1) | 2023.11.17 |
| [Elasticsearch] Elasticsearch 기본 개념 및 장단점 (0) | 2023.11.07 |




