OpenSearch에서 허깅페이스를 활용해서 커스텀모델을 통해 직접 한국어 임베딩을 할 수 있도록 만들어보겠습니다.
아래의 OpenSearch 공식문서를 기반으로 하되, 제대로 작동하지 않아서 많은 것들을 찾아보고 확인하며 겪은 내용이므로 혹여나 잘 못 작성된 부분이 있다면 부드러운 댓글 작성 부탁드립니다.
https://docs.opensearch.org/docs/latest/ml-commons-plugin/custom-local-models/
Custom models
Custom local models Introduced 2.9
docs.opensearch.org
https://huggingface.co/jhgan/ko-sroberta-multitask
jhgan/ko-sroberta-multitask · Hugging Face
ko-sroberta-multitask This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. Usage (Sentence-Transformers) Using this model becomes easy wh
huggingface.co
한국어 임베딩 모델의 경우 위 모델을 사용하였습니다.
먼저 OpenSearch에 모델을 올리기 위한 방법이 여러가지가 존재하는데, 그 중에서 url을 활용하여 직접 OpenSearch에 모델을 올릴 수 있습니다.
이를 위해서 AWS를 활용한다거나, 혹은 Filepath를 활용한다거나 하는데 저는 간단하게 Github release를 활용해서 진행해보겠습니다.
릴리즈를 진행하려면 일단, 파일이 올라가 있어야 됩니다.
파일이 없으면 릴리즈를 진행할 수 없습니다.
그래서 간단하게 REAME 파일을 만들었습니다.
여기서 Tags를 클릭합니다.
Create a new release를 클릭합니다.
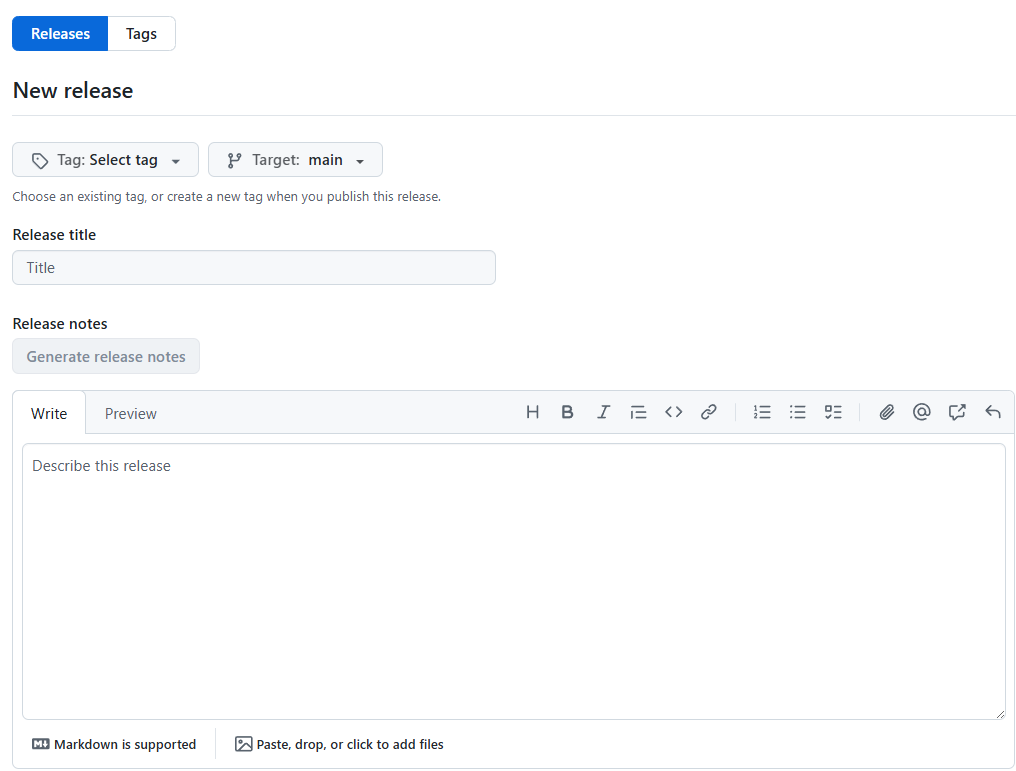
Tag:Select Tag에 v1.1을 입력합니다.
릴리즈 타이틀에는 정한 이름을 넣어줍니다.
KURE-v1.1 OpenSearch Compatible
그러고 나서 아래에 넣을 zip 파일을 넣어주면 끝!
이렇게 깃허브 릴리즈 준비가 끝났습니다.
이제 다음으로 .zip 파일을 만들어주겠습니다.
import torch
import torch.nn as nn
from typing import Dict
import zipfile
import os
from pathlib import Path
class OpenSearchMLWrapper(nn.Module):
"""
OpenSearch ML Commons 호환 래퍼
Dict[str, Tensor] 입력을 개별 텐서로 분해하여 원본 모델에 전달
"""
def __init__(self, base_model):
super().__init__()
self.base = base_model
def forward(self, inputs: Dict[str, torch.Tensor]) -> torch.Tensor:
"""
ML Commons가 전달하는 딕셔너리 형태의 입력을 처리
Args:
inputs: {"input_ids": Tensor, "attention_mask": Tensor}
Returns:
embeddings: 문장 임베딩 벡터
"""
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
return self.base(input_ids, attention_mask)
def wrap_existing_model(model_path: str, output_path: str):
"""
기존 TorchScript 모델을 OpenSearch ML 호환 형태로 래핑
Args:
model_path: 원본 모델 파일 경로
output_path: 래핑된 모델 저장 경로
"""
print(f"기존 모델 로드 중: {model_path}")
# 원본 모델 로드
try:
original_model = torch.jit.load(model_path)
print(f"원본 모델 시그니처: {original_model.forward.schema}")
except Exception as e:
print(f"모델 로드 실패: {e}")
return False
# 래퍼로 감싸기
wrapped_model = OpenSearchMLWrapper(original_model)
# 예제 입력으로 스크립팅 테스트
example_inputs = {
"input_ids": torch.randint(0, 1000, (1, 128), dtype=torch.long),
"attention_mask": torch.ones((1, 128), dtype=torch.long)
}
print("래퍼 모델 테스트 중 입니다")
try:
with torch.no_grad():
test_output = wrapped_model(example_inputs)
print(f"테스트 성공! 출력 형태: {test_output.shape}")
except Exception as e:
print(f"래퍼 테스트 실패: {e}")
return False
# TorchScript로 변환
print("TorchScript 변환 중 입니다")
try:
# Script 방식으로 변환 (Trace보다 안정적)
scripted_model = torch.jit.script(wrapped_model)
# 변환된 모델 테스트
scripted_output = scripted_model(example_inputs)
print(f"마침내 스크립트 변환 성공! 출력 형태: {scripted_output.shape}")
print(f"새 모델 시그니처: {scripted_model.forward.schema}")
except Exception as e:
print(f"스크립트 변환 실패: {e}")
# Trace 방식 시도
try:
print("Trace 방식으로 재시도 중 입니다")
scripted_model = torch.jit.trace(wrapped_model, example_inputs)
scripted_output = scripted_model(example_inputs)
print(f"마침내 Trace 변환 성공! 출력 형태: {scripted_output.shape}")
except Exception as e2:
print(f"Trace 변환도 실패: {e2}")
return False
# 저장
try:
scripted_model.save(output_path)
print(f"래핑된 모델 저장 완료: {output_path}")
return True
except Exception as e:
print(f"모델 저장 실패: {e}")
return False
def create_new_zip_package(original_zip: str, new_model_path: str, output_zip: str):
"""
새로운 래핑된 모델로 ZIP 패키지 생성
Args:
original_zip: 원본 ZIP 파일
new_model_path: 새로운 모델 파일
output_zip: 출력 ZIP 파일
"""
print(f"새 ZIP 패키지 생성: {output_zip}")
temp_dir = Path("temp_repack")
temp_dir.mkdir(exist_ok=True)
try:
# 원본 ZIP에서 파일들 추출 (모델 파일 제외)
with zipfile.ZipFile(original_zip, 'r') as original:
for file_info in original.filelist:
if not file_info.filename.endswith('.pt'):
# 모델 파일이 아닌 것들만 추출
original.extract(file_info.filename, temp_dir)
# 새 ZIP 생성
with zipfile.ZipFile(output_zip, 'w', zipfile.ZIP_DEFLATED) as new_zip:
# 새로운 모델 파일 추가
new_zip.write(new_model_path, "pytorch_model.pt")
# 기타 파일들 추가
for file_path in temp_dir.rglob('*'):
if file_path.is_file():
arc_path = file_path.relative_to(temp_dir)
new_zip.write(file_path, arc_path)
print(f"새 ZIP 패키지 생성 완료: {output_zip}")
# 임시 디렉토리 정리
import shutil
shutil.rmtree(temp_dir, ignore_errors=True)
return True
except Exception as e:
print(f"ZIP 패키지 생성 실패: {e}")
return False
def main():
"""메인 실행 함수"""
print("=== OpenSearch ML Commons 호환 모델 래퍼 ===\n")
import glob
# .pt 파일 찾기
pt_files = glob.glob("**/*.pt", recursive=True)
if not pt_files:
print("오류: .pt 파일을 찾을 수 없습니다.")
return
original_model = pt_files[0] # 첫 번째 .pt 파일 사용
print(f"발견된 모델 파일: {original_model}")
wrapped_model = "pytorch_model_wrapped.pt"
original_zip = "korean-embedding-opensearch.zip"
new_zip = "korean-embedding-opensearch-fixed.zip"
# 기존 모델 래핑
if not wrap_existing_model(original_model, wrapped_model):
print("오류: 모델 래핑 실패")
return
# 새 ZIP 패키지 생성
if not create_new_zip_package(original_zip, wrapped_model, new_zip):
print("오류: ZIP 패키지 생성 실패")
return
# 해시값 계산
import hashlib
def calculate_sha256(file_path):
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
sha256_hash.update(chunk)
return sha256_hash.hexdigest()
file_size = os.path.getsize(new_zip)
sha256_hash = calculate_sha256(new_zip)
print(f"\n수정 완료!")
print(f"새 파일: {new_zip}")
print(f"파일 크기: {file_size:,} bytes")
print(f"SHA256: {sha256_hash}")
# OpenSearch 등록 명령어 생성
print(f"\nOpenSearch 등록 명령어:")
print("="*50)
print(f"""POST /_plugins/_ml/models/_register
{{
"name": "korean-sroberta-embedding-fixed",
"version": "1.0.1",
"description": "Fixed Korean SRoBERTa embedding model for OpenSearch ML",
"function_name": "TEXT_EMBEDDING",
"model_format": "TORCH_SCRIPT",
"model_group_id": "{model_group_id}",
"model_content_size_in_bytes": {file_size},
"model_content_hash_value": "{sha256_hash}",
"model_config": {{
"model_type": "roberta",
"embedding_dimension": 768,
"framework_type": "SENTENCE_TRANSFORMERS",
"pooling_mode": "MEAN",
"normalize_result": true
}},
"url": "https://github.com/YOUR_USERNAME/YOUR_REPO/releases/download/v1.1/{new_zip}"
}}""")
if __name__ == "__main__":
main()

SHA256값과 파일의 크기 같은 경우에는 활용해야 되기 때문에 꼭 알아둬야 합니다.
이제 이렇게 만들어진 .zip을 넣어줍니다.
url의 경우 : https://github.com/Createyouracccount/korean_embedding_model_v3/releases/download/v1.3/korean-embedding-opensearch-fixed.zip 를 직접 구글 검색창에 넣어보면, 다운로드가 진행됨을 확인할 수 있습니다. 굳이 다운로드 받지 말고, 다운로드가 진행되는것이 확인된다면, 다음 단계로 넘어가겠습니다.
이게 에러가 정말 많이 발생했었는데,
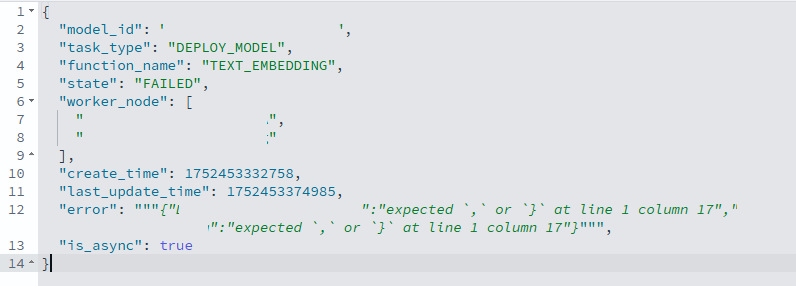
이런 에러도 발생했고,
(이 에러가 발생할 때 모델은 https://huggingface.co/nlpai-lab/KURE-v1 를 사용했었습니다.)
또 다른 에러로
"error": """{"{node_id}":"forward() Expected a value of type 'Tensor' for argument 'input_ids' but instead found type 'Dict[str, Tensor]'.\nPosition: 1\nDeclaration: forward(torch.KoSimCSEModel self, Tensor input_ids, Tensor attention_mask) -> Tensor"," {node_id} ":"forward() Expected a value of type 'Tensor' for argument 'input_ids' but instead found type 'Dict[str, Tensor]'.\nPosition: 1\nDeclaration: forward(torch.KoSimCSEModel self, Tensor input_ids, Tensor attention_mask) -> Tensor"}"""
이런 에러도 만났습니다.
참으로 쉽지 않은 에러였습니다.
여러가지 에러를 정말 많이 만났는데 이게 결국에는 가장 큰 안 됐던 이유가 zip 파일을 만듦에 있어서 문제가 있었기 때문이었습니다.
그러므로 꼭 zip 파일을 만들 때 제대로 만들고, 깃허브에 제대로 릴리즈를 해서 불러온 뒤 사용해야 됩니다.
POST /_plugins/_ml/models/_register
{
"name": "korean-sroberta-embedding-fixed",
"version": "1.0.1",
"description": "Last Try Korean SRoBERTa embedding model for OpenSearch ML",
"function_name": "TEXT_EMBEDDING",
"model_format": "TORCH_SCRIPT",
"model_group_id": "{model_group_id}",
"model_content_size_in_bytes": 406890569,
"model_content_hash_value": "SHA_256",
"model_config": {
"model_type": "roberta",
"embedding_dimension": 768,
"framework_type": "SENTENCE_TRANSFORMERS",
"pooling_mode": "MEAN",
"normalize_result": true
},
"url": "https://github.com/Createyouracccount/korean_embedding_model_v3/releases/download/v1.3/korean-embedding-opensearch-fixed.zip"
}
GET /_plugins/_ml/tasks/{task_id}
GET /_plugins/_ml/models/{model_id}
POST /_plugins/_ml/models/{model_id}/_deploy
각각을 이를 통해서 확인합니다.
마지막 POST를 통해서 만들어진 모델을 deploy합니다.
# 배포 태스크 확인
GET /_plugins/_ml/tasks/_search
{
"query": {
"term": {
"model_id": "{model_id}"
}
},
"sort": [
{
"create_time": {
"order": "desc"
}
}
],
"size": 1
}
이렇게 배포 task를 확인해보면~~~
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": ".plugins-ml-task",
"_id": "{id}",
"_version": 3,
"_seq_no": 322,
"_primary_term": 2,
"_score": null,
"_source": {
"last_update_time": xxxxxxxxx,
"create_time": xxxxxxxxx,
"is_async": true,
"function_name": "TEXT_EMBEDDING",
"worker_node": [
"{worker_node}",
"{worker_node}"
],
"model_id": "{model_id}",
"state": "COMPLETED",
"task_type": "DEPLOY_MODEL"
},
"sort": [
xxxxxxxxx
]
}
]
}
}
아주 야무지게 잘 나온 것을 확인할 수 있습니다!!
다음에는 이를 활용한 Semantic Search를 만드는 방법에 대해서 알아보겠습니다!
'검색엔진 > Opensearch' 카테고리의 다른 글
| OpenSearch HuggingFace 한국어 모델 활용 임베딩 및 서치까지 (5) | 2025.07.17 |
|---|---|
| OpenSearch를 활용한 형태소 분석과 중복 단어 제거 (0) | 2025.03.28 |
| [opensearch] 인덱스 snapshop 뜨는 방법 (0) | 2025.01.20 |
| 오픈서치 기본 설치 (0) | 2024.09.24 |




