
세세하게 살펴보기엔 알아야 할 지식들이 많으니 간단하게만 살펴보자.
Microsoft에서 발표하였으며, 2023년 ICLR에 Accept 된 [논문]이다.
논문에서도 3장에서 딱 두 가지의 차별점만 언급한다.
1. DISENTANGLED ATTENTION
2. ENHANCED MASK DECODER
간단하게 살펴보자
DISENTANGLED ATTENTION
이런 짓거리를 왜 하는지를 이해하려면 Transformer의 구조적 이해가 필수적이다.
사실 Transformer에서도 충분한 고려를 진행하고 있지만, 부족했나보다.
핵심은 Position이다.

Transformer의 장점이 무엇인가.
기존 RNN에서 순차적으로 처리되던 정보를, Matrix형태로 표현할 수 있게 되었다.
그런데 Matrix의 개별 Row는 Embedding Vector의 정보일 뿐, 어떤 "위치적" 정보도 존재하지 않는다.
당연하지만 위치정보는 상당히 중요한데 ...
같은 단어(토큰)라 할지라도, 문장의 맨 앞에서 쓰이는 경우와 맨 뒤에서 쓰이는 경우가 다를 가능성이 있기 때문이다.
그렇기 때문에 Transformer에서도 Positional Encoding이라는 작업을 통해
Input Embedding에 해당 Value를 합산해주는 메커니즘을 가지고 있다.
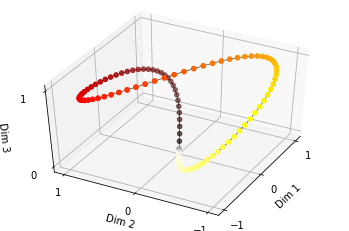
실제로 이 과정은 Sinusoidal Positional Encoding이라는 과정을 통해 진행되는데
간단하게 설명하자면, D_model 차원의 개수만큼의 파동함수가 존재하고,
해당 파동함수의 주기가 일정 간격을 두고 상이한 형태로 존재할 때
개별 차원에서 주기가 상이한 파동함수의 공간상의 자취를 통해 위치정보를 표현하는 것이다.
이것을 그림으로 표현하면 아래와 같다.
실제로 이것만 살펴봐도 하루종일이니 이 쯤 하고 넘어가자.
이런 Sinusoidal Positional Encoding도 상당히 강력하지만 ...
단순히 효과적인 Value를 합산해주는 메커니즘일 뿐인 것이다.
그래서 DeBERTa는 Disentangled Attention이라는 작업을 통해
Content 뿐만 아니라, Position에 대해서도 고려하고자 한 것이다.
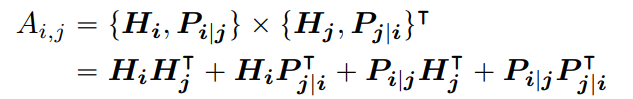
핵심은 간단하다.
Attention Score는, 총 4가지 부분으로 나눠진다는 것이다.
여기서 H는 Content Vector를 의미하며
P 는 Position Vector를 의미한다고 볼 수 있겠다.
H는 Token의 Embedding을 통해 달성할 수 있으며
P의 경우 i, j의 상대적인 위치에 따라 아래의 수식과 같이 계산된다.
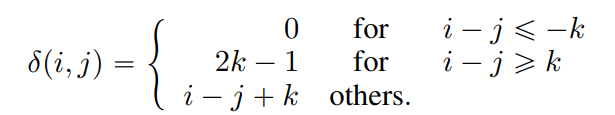
상기 수식에서 K는 최대 관계 거리(Maximum Realative Distance)를 의미한다고 한다.
즉 어디까지의 관계를 포착할지에 대한 Threadhold라고 볼 수 있겠다.
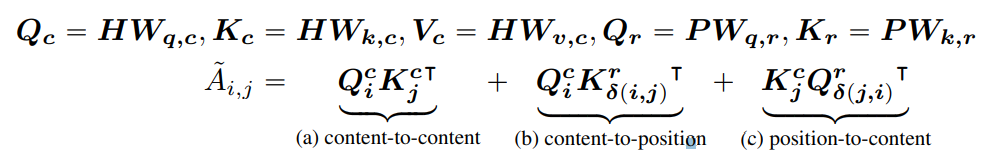
이후 Weight Matrix와의 연산을 통해 실제 Q, K, V,를 구하고
이를 다음과 같이 합산하여 실제 Attention Score를 산출하게 되는 것이다.
즉 기존에 진행하는 Attention Score의 산출 수식이, 아주 조금 변형되었을 뿐인 것이다.
이런 방식을 통해 총 3가지의 Information을 효과적으로 합치고 있다.
(앞에서는 4가지로 표현되었지만, position-to-position은 유의미한 정보가 아니라 제외한다 함)
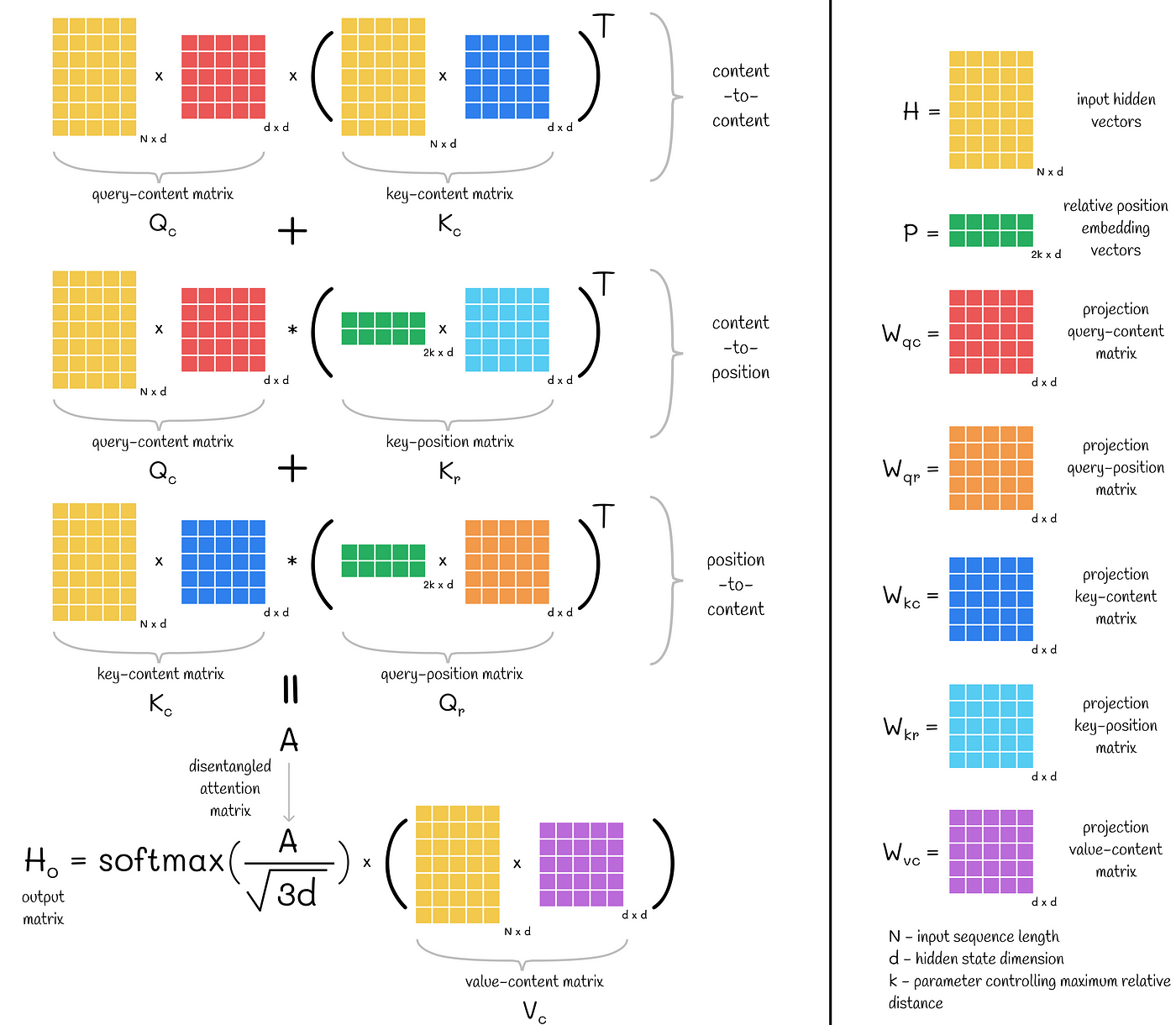
너무나도 잘 표현된 그림이 있어 그대로 가져왔다.
Input은 Token이 Embedding된 Matrix H이고
P는 아까 말한 방식으로 산출된 Matrix이다.
Output은 이러한 Attention을 통해 산출되는 H_0이다.
첫 번째 과정 Q_c 및 K_c를 구한 뒤 V_c와 곱하는 과정이 기존 Transformer에서 수행하는 것이고
(실제 Transformer에서 진행하는 Scaled Dot-Product Attention과 상수는 조금 차이가 있다)
나머지는 DeBERTa에서 추가한 것이라고 보면 되겠다.
ENHANCED MASK DECODER
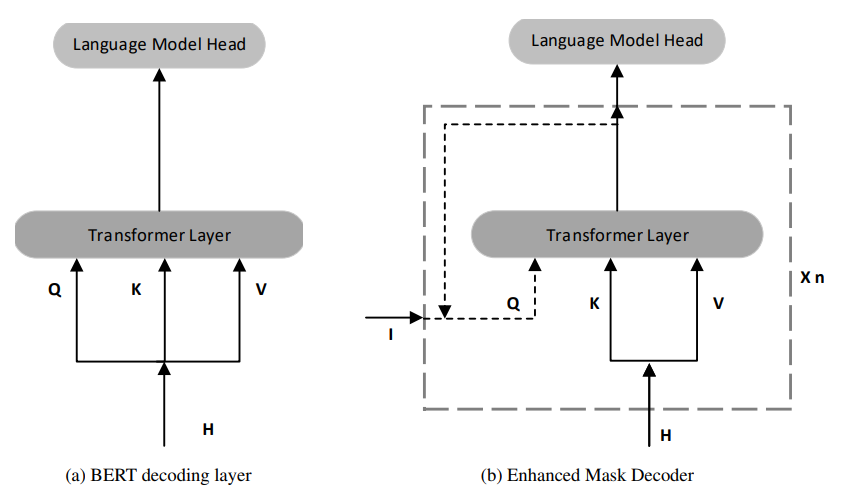
엄청 거창한 차이가 있는 것은 아니다.
실제로 눈여겨 볼 것은, 기존 디코더의 경우 H,
즉 Input Hidden State를 통해 Q, K, V를 모두 얻고 이것이 Layer로 입력된다는 것이지만
EMD(Enhanced Mask Decoder)의 경우에는 Q의 값만 이상한 값(I)을 가지고 온다는 것이다.
왜 이런 짓을 하는가?
최근 언어 모델은 MLM(Masked Language Modeling)이라는 기법을 통해 학습을 진행한다.
확률적으로 Token을 MASK로 변환시키고, 나머지 Token을 이용해 MASK를 예측하는 방식의 학습이다.
문제는 이 과정에서 앞서 제시한 Disentangled Attention에 한계가 존재하기 때문이다.
예를 들어, a new store opened beside the new mall라는 문장이 있다고 가정하자
이 때 문장이 a new [MASK] opened beside the new [MASK] 로 바뀐다고 본다면
두 가지 MASK 모두 new라는 단어를 바로 직전에 위치시키게 된다.
문제는 Disentangled Attention은 두 가지 토큰의 "상대적 위치"만을 모델링 하고 있을 뿐
기존 Sinusoidal Positional Encoding과 같이 "절대적 위치"를 모델링하지 않는다는 것이다.
반면 위와 같은 문제상황에서는 토큰의 절대적 위치 정보까지도 분명하게 고려해야 한다.
EMD에서는 이러한 문제를 해결하고자
앞서 언급한 I 에 절대적 위치정보를 넣어, 이를 통해서 Q의 Value를 수정하고 있다.
저자들은 Attention 과정에서 절대적 위치정보는, 상대적 위치 학습을 방해하는 요인으로 보고 있지만
실제 문장의 관계를 살필 때에는 이러한 정보가 들어가는 것이 효과가 좋다고 밝히고 있다.
다만 I에 값에 입력될 수 있는 정보는 이것만 존재하는 것이 아니며
향후 연구에서 더욱 효과적인 정보가 있을 수 있는지 살펴볼 것을 이야기하고 있다.
아주 간단히 핵심 두 가지에 대해서 살펴보았다.
나머지는 거의 Transformer와 유사하다.
'A.I.(인공지능) & M.L.(머신러닝) > LLM' 카테고리의 다른 글
| Custom Model Training을 위한 Hugging Face Trainer 구조 파악하기 (0) | 2025.01.22 |
|---|---|
| DeepSeek-V3 (0) | 2025.01.14 |
| eCeLLM 논문 리뷰: Instruction Tuning for E-Commerce (Data Example 추가) (0) | 2024.12.23 |
| DSPy(Declarative Self-improving Language Programs, pythonically) (1) | 2024.12.16 |
| Graph Retrieval Augmented Generation(Graph-RAG) 톺아보기 (1) | 2024.12.05 |

