중국 지푸 AI와 칭화대학교 연구진이 오픈 소스 텍스트-비디오 모델인 ‘코그비디오X(CogVideoX)’를 Huggingface 및 Arxiv에 공개하였는데 코그비디오X 는 2, 5b 두가지가 공개되었는데, 코그비디오X-5B는 텍스트 프롬프트를 통해 최대 6초 길이 720×480 해상도의 고품질 비디오를 생성할 수 있다고 밝혔다.
CogVideoX는 Text-to-video generation을 위한 대규모 diffusion transformer 모델이며, 텍스트 prompt만으로 고품질 비디오를 생성할 수 있다. Arxiv에 게재되어진 논문에 의하면 다음과 같은 기술을 적용하여 코드비디오X를 학습한 것으로 알려졌다.
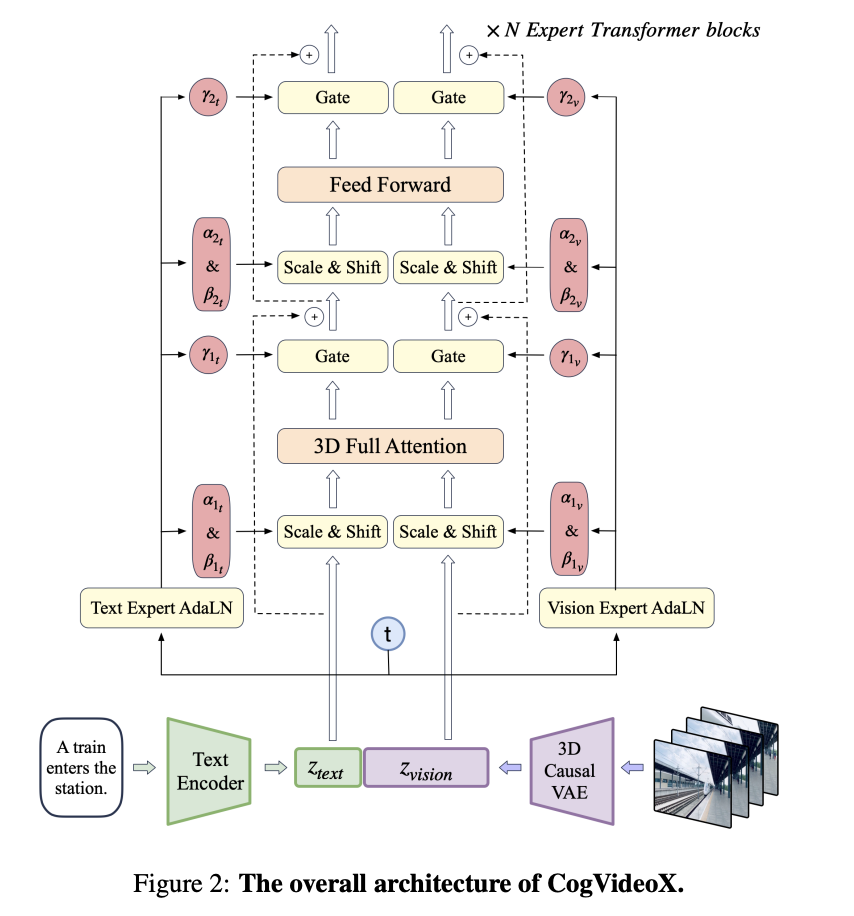
1. 기술 방법론
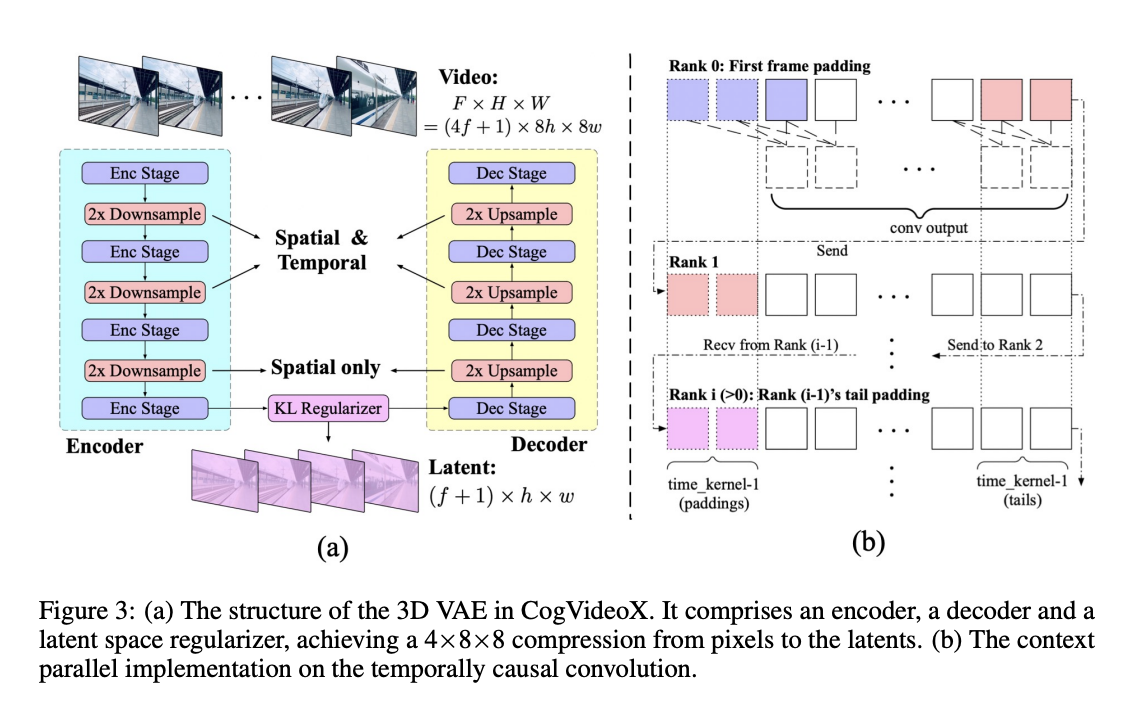
1) 3D Variational Autoencoder (VAE) 활용
3D Causal VAE는 비디오 데이터를 효율적으로 처리하기 위한 비디오 압축 모듈이다. 비디오 데이터는 시간적 정보와 공간적 정보를 모두 포함하므로, 이미지보다 훨씬 더 큰 데이터 양을 가지게 되는데, 이를 해결하기 위해 3D VAE를 사용하여 비디오 데이터를 공간적 및 시간적으로 압축한다. 이 VAE는 ResNet 블록을 사용한 다운샘플링과 업샘플링을 통해 4×8×8의 높은 압축 비율을 달성하는데, 다운샘플링의 첫 두 번은 공간 및 시간 차원을 모두 적용하며, 마지막 단계에서는 공간적 샘플링만 수행하여, 4배의 시간 압축과 8×8의 공간 압축을 구현한다. 또한, 일시적으로 인과적인 컨볼루션을 사용하여 미래 정보가 현재나 과거의 예측에 영향을 미치지 않도록 하고, GPU 메모리 사용을 최적화하기 위해, 시간 차원에서의 병렬 처리가 도입했다. 이 3D VAE는 낮은 해상도와 적은 프레임 수로 초기 훈련한 후, 더 높은 해상도와 긴 비디오를 처리하기 위해 미세 조정하는 두 단계로 학습된다.
2) Expert Transformer 도입
Expert Transformer는 비디오와 텍스트 데이터를 효과적으로 처리하기 위해 고안된 Transformer 아키텍처이다. 이 모델에서는 먼저 비디오 잠재 벡터를 공간 차원에서 패치화하여 시퀀스 zvision을 생성하며, 시간적 패치화는 적용하지 않음으로써 이미지와 비디오의 공동 학습이 가능하도록 설계되었다. 비디오 데이터의 위치 인코딩은 3D-RoPE 기법을 통해 이루어진다. 이는 3차원 좌표 각각에 대해 1D-RoPE를 독립적으로 적용하고, 이를 채널 차원에서 결합하여 최종 위치 인코딩을 형성하는 방식이다. 이러한 접근법은 비디오 데이터 학습의 수렴 속도를 유의미하게 개선하는 것으로 확인되었다. 또한, 텍스트와 비디오 임베딩을 시퀀스 입력 단계에서 결합하여 시각적 정보와 의미적 정보의 정합성을 향상시키고자 하였다. 그러나 텍스트와 비디오의 피처 스페이스 간 차이가 크기 때문에, Expert Adaptive Layernorm을 도입하여 두 모달리티를 독립적으로 처리하는 방식을 채택하였다. 이는 피처 스페이스 간 정합성을 높이면서도 추가적인 파라미터의 증가를 최소화하는 효과를 가져온다. 마지막으로, 기존의 분리된 공간 및 시간 주의 메커니즘 대신, 3D 텍스트-비디오 하이브리드 주의 메커니즘을 도입하여 학습의 복잡성을 감소시키고, 큰 움직임을 보이는 객체의 일관성을 유지하도록 하였다.
CogVideoX의 훈련 방법론은 이미지와 비디오를 혼합하여 훈련하고, 점진적인 해상도 증가를 통해 모델의 성능을 향상시키는 데 중점을 두고 있다. 이 과정에서 v-prediction과 zero SNR을 사용하며, timestep 샘플링에 있어서 명시적인 균일 샘플링 방법을 도입하여 훈련의 안정성을 높였다.
2. 학습 방법론
1) Frame Pack
기존의 비디오 훈련 방식은 고정된 프레임 수를 가진 이미지와 비디오를 공동 훈련하는데, 이는 이미지와 비디오 간의 프레임 수 차이로 인해 모델이 두 가지 생성 모드로 분리되는 문제를 야기할 수 있다. 또한, 고정된 길이의 비디오로 훈련하기 위해 짧은 비디오는 버리고 긴 비디오는 자르기 때문에 데이터의 전체 활용이 어려워진다. 이러한 문제를 해결하기 위해, 다양한 길이의 비디오를 동일한 배치에서 훈련하는 Frame Pack 방식을 도입하였다. 이 방법은 Patch’n Pack에서 영감을 받아, 비디오를 동일한 배치 내에서 일관된 데이터 형태로 유지하며 훈련할 수 있게 한다
2) 해상도 점진적 훈련
CogVideoX의 훈련은 저해상도 훈련, 고해상도 훈련, 그리고 고품질 비디오 미세 조정의 세 단계로 나뉜다. 저해상도 훈련을 통해 모델이 초기에는 거친 특징을 학습하도록 하고, 이후 고해상도 훈련을 통해 세부 사항을 포착하는 능력을 강화한다. 이러한 단계적 훈련은 직접 고해상도로 훈련하는 것보다 전체 훈련 시간을 줄이는 데 도움이 된다. 또한, 저해상도에서의 위치 인코딩을 고해상도로 변환할 때, 전역 정보를 더 잘 유지하는 보간법과 국부적 세부 정보를 보존하는 외삽법 중, RoPE가 상대적 위치 인코딩이라는 점을 고려해 외삽법을 선택하였다. 마지막 미세 조정 단계에서는 고품질 비디오 데이터로 훈련하여, 생성된 자막과 워터마크를 제거하고 시각적 품질을 향상시키는 반면, 모델의 의미적 능력은 약간 저하되는 현상이 관찰되었다.
3) 명시적 균일 샘플링
기존의 확산 모델 훈련에서는 타임스텝 t를 균일하게 샘플링하지만, 실제로는 샘플링이 충분히 균일하지 않아 손실 변동이 커지는 문제가 발생한다. 이를 해결하기 위해, 타임스텝 범위를 n개의 구간으로 나누고, 각 데이터 병렬 그룹이 해당 구간 내에서 균일하게 샘플링하는 명시적 균일 샘플링 방법을 제안하였다. 이 방법은 타임스텝 분포를 더욱 균일하게 만들어 훈련 중 손실 곡선을 안정시키고, 손실 수렴 속도를 가속화하는 효과를 보였다.

3. 데이터
CogVideoX 모델의 훈련을 위해, 고품질의 비디오 클립과 텍스트 설명이 포함된 데이터셋을 구성하였으며, 비디오 필터링 및 자막 생성 모델을 통해 데이터를 정제하였다. 최종적으로 약 3,500만 개의 단일 샷 클립이 남았으며, 각 클립의 평균 길이는 약 6초이다.
1) 비디오 필터링
비디오 생성 모델이 세계의 동적 정보를 학습하기 위해서는 높은 품질의 비디오 데이터가 필요하다. 하지만 필터링되지 않은 비디오 데이터는 두 가지 주요 이유로 인해 매우 노이즈가 많다. 첫째, 비디오는 인간에 의해 만들어지므로, 인위적인 편집이 원래의 동적 정보를 왜곡할 수 있다. 둘째, 촬영 중 발생하는 카메라 흔들림이나 저급 장비 사용으로 인해 비디오의 품질이 크게 저하될 수 있다. 이러한 비디오 데이터의 본질적인 품질 외에도, 모델 훈련에 얼마나 유용한지에 대한 평가도 필요하다. 동적 정보가 부족하거나 동적 연결성이 결여된 비디오는 모델 훈련에 해롭다고 간주된다. 이를 해결하기 위해, 다음과 같은 부정적 레이블을 개발하여 저품질 비디오 데이터를 제거하였다:
- Editing: 재편집이나 특수 효과 등 인위적인 처리가 이루어진 비디오
- Lack of Motion Connectivity: 이미지 전환 시 동적 연결성이 부족한 비디오
- Low Quality: 시각적으로 불분명하거나 카메라 흔들림이 과도한 비디오
- Lecture Type: 강의나 토론과 같이 사람이 말하는 데 초점이 맞춰져 있는 비디오
- Text Dominated: 화면의 대부분이 텍스트로 채워져 있거나 텍스트에 중점을 둔 비디오
- Noisy Screenshots: 휴대전화나 컴퓨터 화면을 녹화한 노이즈가 많은 비디오
이러한 레이블을 사용하여 약 2만 개의 비디오 샘플을 분석하고, Video-LLaMA 모델을 기반으로 여러 필터를 훈련시켜 저품질 비디오 데이터를 걸러냈다. 또한, 모든 훈련 비디오의 광학 흐름 점수와 이미지 미적 점수를 계산하여 훈련 중에 임계값 범위를 동적으로 조정함으로써 생성된 비디오의 유연성과 미적 품질을 보장하였다.
2) 비디오 자막 생성
대부분의 비디오 데이터는 텍스트 설명이 없으므로, 텍스트-비디오 모델의 필수적인 훈련 데이터를 제공하기 위해 비디오 데이터를 텍스트 설명으로 변환해야 한다. 기존의 비디오 자막 데이터셋은 대개 짧은 설명만을 제공하여 비디오의 내용을 포괄적으로 설명하지 못한다. 이를 해결하기 위해, 이미지 자막을 비디오 자막으로 생성하는 Dense Video Caption Data Generation 파이프라인을 구축하였다. 먼저, Panda70M 비디오 자막 모델을 사용하여 비디오에 대해 짧은 자막을 생성하고, 이후 Stable Diffusion 3와 CogView3에서 사용된 이미지 자막 모델 CogVLM을 활용하여 비디오 내 각 프레임에 대한 밀도 높은 이미지 자막을 생성한다. 그런 다음, GPT-4를 사용하여 모든 이미지 자막을 요약하여 최종 비디오 자막을 생성한다. 이미지 자막에서 비디오 자막으로의 전환을 가속화하기 위해, GPT-4에서 생성된 요약 데이터를 사용하여 Llama2 모델을 미세 조정하여 대규모 비디오 자막 데이터 생성을 가능하게 하였다.
이와 같은 과정을 통해 생성된 자막 데이터는 CogVideoX 모델을 훈련하는 데 사용되었으며, 다음 세대의 CogVideoX 훈련을 위해 CogVLM2-Caption이라는 엔드 투 엔드 비디오 이해 모델을 미세 조정하여 비디오 자막 생성 프로세스를 더욱 가속화하였다. Appendix E에서는 CogVLM2-Caption 모델을 사용하여 생성된 비디오 자막을 입력으로 하여 CogVideoX가 새로운 비디오를 생성하는 비디오-투-비디오 생성 예시를 제시하였다.
4. 실증 평가
이 섹션에서는 CogVideoX의 성능을 자동화된 메트릭 평가와 인간 평가라는 두 가지 주요 방법을 통해 분석한다. CogVideoX 모델은 서로 다른 파라미터 크기로 훈련되었으며, 현재 2B와 5B 모델에 대한 결과를 제시한다. 향후 더 큰 모델들도 훈련 중에 있으며, 텍스트-비디오 생성의 발전을 촉진하기 위해 모델 가중치는 오픈소스로 공개될 예정이다.
1) 자동화된 메트릭 평가
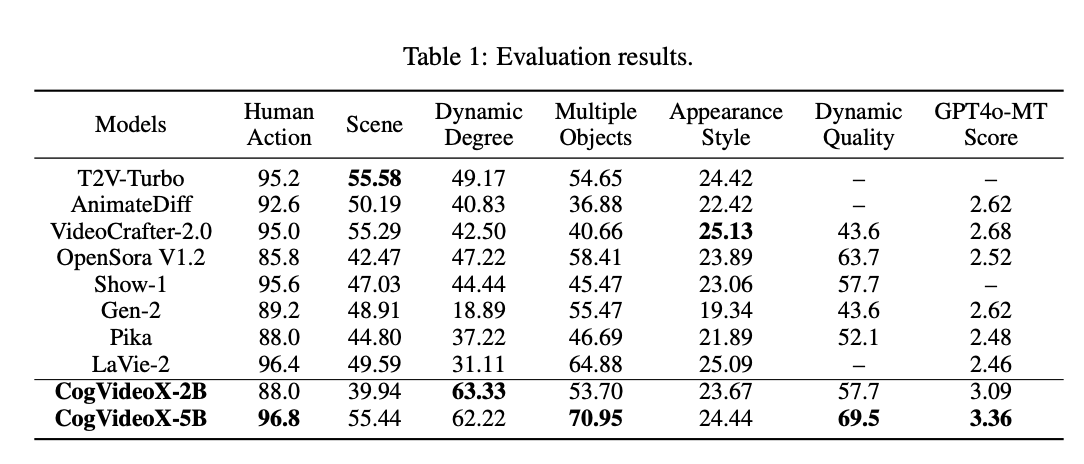
- 기준 모델: 성능 비교를 위해 공개적으로 접근 가능한 최고 성능의 텍스트-비디오 모델을 기준으로 삼았다. 이에는 T2V-Turbo (Li et al., 2024), AnimateDiff (Guo et al., 2023), VideoCrafter2 (Chen et al., 2024a), OpenSora (Zheng et al., 2024b), Show-1 (Zhang et al., 2023a), Gen-2 (runway, 2023), Pika (pik, 2023), 그리고 LaVie-2 (Wang et al., 2023b)가 포함된다.
- 평가 지표: 텍스트-비디오 생성의 평가를 위해 VBench (Huang et al., 2024)에서 제시한 여러 메트릭을 사용하였다. 선택된 메트릭으로는 Human Action, Scene, Dynamic Degree, Multiple Objects, 그리고 Appearance Style이 있다. VBench는 생성된 비디오의 품질을 자동으로 평가하는 도구로 설계되었다. 이 외에도 Dynamic Quality (Liao et al., 2024)와 GPT4o-MTScore (Yuan et al., 2024) 같은 비디오 평가 도구를 추가로 활용하였다. Dynamic Quality는 비디오의 동적 특성을 평가하며, 다양한 품질 메트릭과 동적 점수를 통합하여 비디오 동작과 품질 간의 부정적 상관관계에서 발생할 수 있는 편향을 줄인다. GPT4o-MTScore는 타임랩스 비디오의 변화를 세밀하게 평가하는 메트릭으로, 비디오의 역동성을 평가하는 데 사용된다.
- 결과: CogVideoX는 7개 메트릭 중 5개에서 최고 성능을 보였으며, 나머지 2개 메트릭에서도 경쟁력 있는 결과를 나타냈다. 이는 CogVideoX가 비디오 생성 품질뿐만 아니라 복잡한 동적 장면 처리에서도 탁월함을 입증하는 것이다. 또한, Figure 1에서는 CogVideoX의 성능 우위를 시각적으로 나타낸 레이더 차트를 보여준다.
2) 인간 평가
자동화된 평가 이외에도, Kling (Team, 2024)과 CogVideoX를 비교하는 인간 평가가 수행되었다. 100개의 엄선된 프롬프트가 사용되었으며, 평가자들은 무작위로 설정된 비디오에 대해 블라인드 평가를 진행하였다. 평가자들은 각 비디오에 대해 0에서 1까지의 점수를 부여하고, 전체 점수는 0에서 5까지의 척도로 평가되었다. 이때, 지시 사항을 따르지 않는 비디오는 총점이 2점을 초과할 수 없도록 설정되었다. Table 2의 결과는 CogVideoX가 모든 측면에서 Kling보다 더 높은 평가를 받았음을 보여준다. 인간 평가에 대한 추가 세부 사항은 부록 F에 제시되어 있다.

5) 결론
이 논문에서는 최첨단 텍스트-비디오 확산 모델인 CogVideoX를 소개하였다. 본 모델은 3D VAE와 Expert Transformer 아키텍처를 활용하여 일관된 장시간 비디오 생성이 가능하다. 포괄적인 데이터 처리 파이프라인과 비디오 재캡션 방법을 도입하여 생성된 비디오의 품질과 의미적 정렬을 크게 개선하였다. 혼합 지속 시간 훈련 및 해상도 프로그레시브 훈련 등의 훈련 기법은 모델의 성능과 안정성을 더욱 강화하였다고 주장했다.
6) 사용 방법
의존성
pip install --upgrade transformers accelerate diffusers imageio-ffmpeg
실행 코드
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
# 원하는 영상을 자세히 설명하는 프롬프트 설정
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
export_to_video(video, "output.mp4", fps=8)
'A.I.(인공지능) & M.L.(머신러닝)' 카테고리의 다른 글
| [ComfyUI] ComfyUI 설치 및 간단 사용법 정리 (1) | 2025.02.05 |
|---|---|
| intel npu acceleration library - window (0) | 2025.02.03 |
| [유치원과정] 트랜스포머 이론 - 인코더 | Multi-Head Attention (0) | 2025.01.05 |
| Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer (2) | 2024.12.02 |
| 런웨이 & 루마 AI API (1) | 2024.09.22 |



