
HuggingFace와 E-Commerce 관련된 자료들 혹은 사업들을 살펴보며
상당히 재미있는 시도들을 많이 발견할 수 있었다.
특히 재밌는 사업 중 하나는 생성형 AI, 그 중에서도 Computer Vision 모델들을 이용한 것이다.


YouTube의 썸네일에서부터, 간단한 숏폼, 쇼츠의 비디오까지도 AI가 만드는 세상이다.
그렇다면, E-Commerce의 영역에서도,
자사의 상품과 AI 모델을 손쉽게 합성할 수 있는 Workflow를 손쉽게 만들 수 있지 않을까?
(물론 이미 많은 곳에서 도전하고 있는 영역이지만, ChatGPT 수준의 간편한 영역에 도달하지는 않았다. 그리고 비싸다 ..)
WebUI & ComfyUI
CV 모델을 이용하는 가장 강력한 양대산맥의 Tool이라고 볼 수 있겠다.
6개월 전만 해도 WebUI가 상당히 강력했지만, 이제는 거의 ComfyUI로 넘어온 추세라고 볼 수 있겠다.
이러한 원인을 굳이 찾아본다면 ...
- LangChain이나 LangGraph와 다르게 이미지 생성 영역은 단일 모델만을 활용하는 경우가 매우 적음
- Prompt Level 수준에서 이미지 조작 능력을 갖추는 것이 쉽지가 않음
- 개별 DownStream Task에 Tune된 LoRA 모델, VAE 등을 교체하며 튜닝하는 것이 일반적
이렇듯 이미지 생성 영역에서는
강력한 단일 모델 + Prompt를 통해 모든 문제를 해결하는 것이 매우 어렵다.
오히려 개별적으로 Tuning된 모델들을 엮고 엮어서 최종적인 결과물을 생성하는 것이 일반적이다.
그러다보니 전체적인 Workflow를 관리하기가 용이한 ComfyUI로 넘어갈 수 밖에 없는 것이다.

Stability Matrix - ComfyUI
작업 환경은 위와 같이 구성하려고 한다.
Stability Matrix는 Python의 Anaconda와 같은 도구라고 보면 되겠다.
WebUI나 ComfyUI 같은 Package 및 Model을 관리하는 도구이다. (오픈소스 아님)
ComfyUI는 CV Model의 Workflow를 구성하는 도구이다 (오픈소스임)
보통 Anaconda는 너무 무겁고 별로라 venv로 넘어가는 추세이지만 ...
Stability Matrix는 그렇게까지 무겁다고 느껴지지 않았다.
상태관리를 위해서라도 꼭 채택하는 것으로 하자.
Stability Matrix - Multi-Platform Package Manager and Inference UI for AI Image Generation
Multi-Platform Package Manager and Inference UI for AI Image Generation. Works with Flux and Stable Diffusion.
lykos.ai
lykos AI에서 제공하는 Stability Matrix이다.
v2.13.3 Stable 버전을 다운받았다. (Win, Mac, Linux 모두 지원하는 것으로 보인다)
설치를 완료하면 바로 Package 설치를 요구한다.
어차피 설치할 것이니 바로 설치하면 된다.

사실 여기까지 했으면 이제 끝이긴 한데 ...
몇 가지 설정을 추가로 진행해보도록 하자.
1. ComfyUI 기본 설정

설치가 끝나면 Packages에 ComfyUI가 보일 것이다.
설정 버튼을 누른 뒤, 맨 아래의 Auto-Launch만 활성화 하자.
일단 Local에서 사용할 것이기에 크게 건드릴 것은 없다.
2. ComfyUI Manage
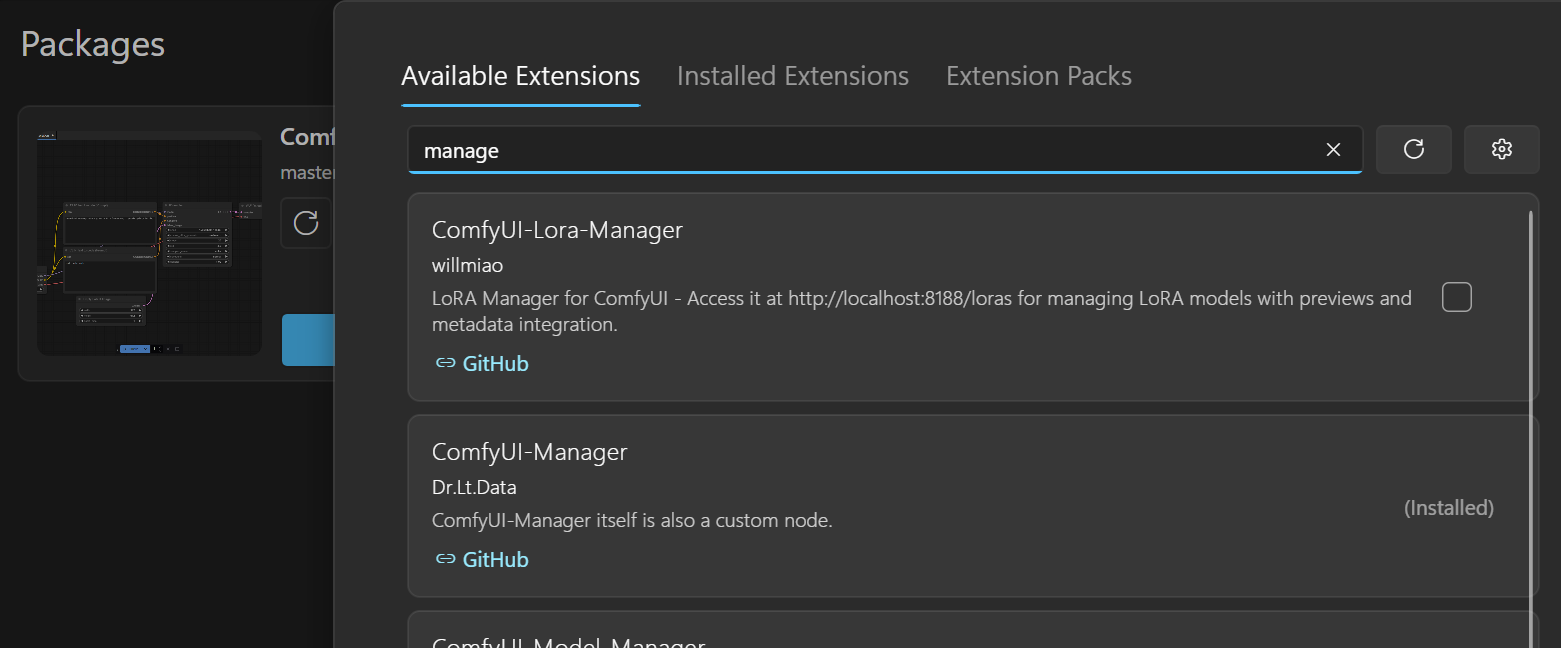
다음으로 설치할 것은, ComfyUI-Manager이다
Custom Node 및 Model 등 편리한 도구가 많으니 일단 설치하자.
3. Model Search

다음은 모델이다.
아직 아무 모델도 설치되지 않았으니 ComfyUI를 실행하면 모델이 없다고 뭐라뭐라 하는 것으로 기억한다.
Stability Matrix는 굳이 CivitAI나 Hugging Face를 돌아다니지 않고도 모델을 쉽게 다운로드 받을 수 있도록 해놓았다.
적당한 것을 골라 Import를 하면 해당 모델이 자동으로 받아진다.
조심할 것은 상단 Filter에서 Model Type을 Checkpoint로 설정한 뒤 내려받도록 하자.
모든 모델은 개별적인 Downstream Task를 가지고 있다.
여기서 Checkpoint로 설정되어야 CV 모델의 Backborn을 다운받을 수 있다.
모델은 보통 다음 3가지를 특화하여 사용되는 것으로 보인다.
- 실사(Realistic)
- 반실사(Mix)
- 만화(Animation & Cartoon)
보통 만화 모델이 생성이 쉬운 편이고, 실사 모델 생성이 더 어려운 느낌이었다.
우리 목표는 실제 모델 광고 포스터를 손쉽게 생성하는 것이니 ... 가장 상위에 있는 Realistic 모델을 받았다.
Run ComfyUI
이제 한 번 켜보자!
Packages로 가서 ComfyUI를 실행하자.
아마 의존성 라이브러리 혹은 GPU 이용을 위한 Torch 및 Tool들을 자동으로 다운로드 받을 것이다.
실행이 완료되면 다음과 같은 화면을 볼 수 있다.

- 왼쪽 사이드바는 노드, 모델, Workflow를 관리한다.
- 우상단 Manage는 아까 설치한 ComfyUI-Manage로 추후 Custom Node 및 Downstream Model 설치에 사용하자.
- 가운데 Workflow가 우리가 관리해야 하는 이미지 생성의 흐름도이다.
(이 기본값이 Default 셋팅으로, [모델 - 프롬프트 - 샘플러 - VAE - 생성된 이미지] 의 기본 Workflow를 구성한다)
(프롬프트는 Positive Prompt와 Negative Prompt로 구성된다)
Diffusion Model에 대해 자세하게 이해하는 것도 좋겠지만 ... 일단 간단하게만 생각하자면
1. 시작값(특정 크기의 노이즈 벡터: Seed에 의해 결정)
2. 해당 값 + Prompt를 통해 Reverse Diffusion 진행 (Sampler)
3. 이렇게 진행된 값을 VAE를 통해 최종적으로 디코딩
이런 느낌으로 생각할 수 있겠다.
때문에 개별적 과정에 개별적 모델을 활용하거나, 프롬프트를 조작하며 결과를 바꿀 수 있는 것이라고 볼 수 있겠다.
그래서 큰 Workflow를 살펴보면, 특정한 Model을 통해 적당히 Sampling하여 노이즈가 있는 이미지를 생성하고
해당 이미지를 여러가지의 VAE가 받아서 다양한 이미지를 생성하기도 한다.
대충 살펴봤으니 생성도 한 번 해보자.
Prompt는 정말 다양하게 존재한다 ... 다양한 시도를 진행했던 사람들의 프롬프트를 조금씩 차용하도록 하자.
https://flatsun.tistory.com/3556
https://letsgotitan.tistory.com/38
다음 사이트들을 참고했다.
positive prompt:
masterpiece, best quality, photorealistic, dramatic lighting, raw photo, ultra realistic details, sharp focus, detailed skin
negative prompt:
Drawings, abstract art, cartoons, surrealist painting, conceptual drawing, graphics, (low resolution:1.4), ((blurry:1.3)), (worst quality:1.3), (low quality:1.3), (thick thighs:1.2), huge breasts, nsfw, bad proportions, big eyes

아무런 것도 건들지 않고, 4070 Laptop GPU로 약 5초정도 소모된다.
다음에는 이것들을 바탕으로 광고 이미지를 합성하는 과정까지 진행해보도록 하자.
'A.I.(인공지능) & M.L.(머신러닝)' 카테고리의 다른 글
| deepseek-r1 vs gemma3 성능 및 품질 비교 (0) | 2025.03.14 |
|---|---|
| intel npu acceleration library - window (0) | 2025.02.03 |
| [유치원과정] 트랜스포머 이론 - 인코더 | Multi-Head Attention (0) | 2025.01.05 |
| Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer (2) | 2024.12.02 |
| 런웨이 & 루마 AI API (1) | 2024.09.22 |




